web scrapping
تفاصيل العمل

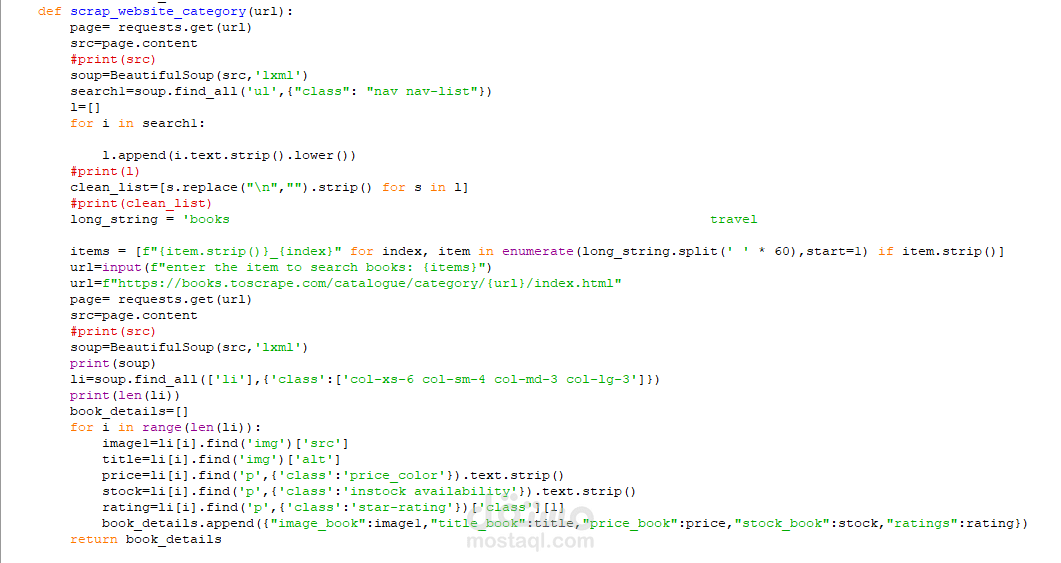

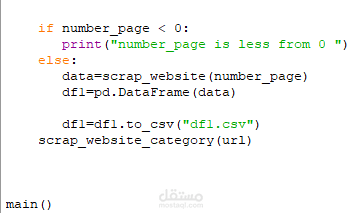
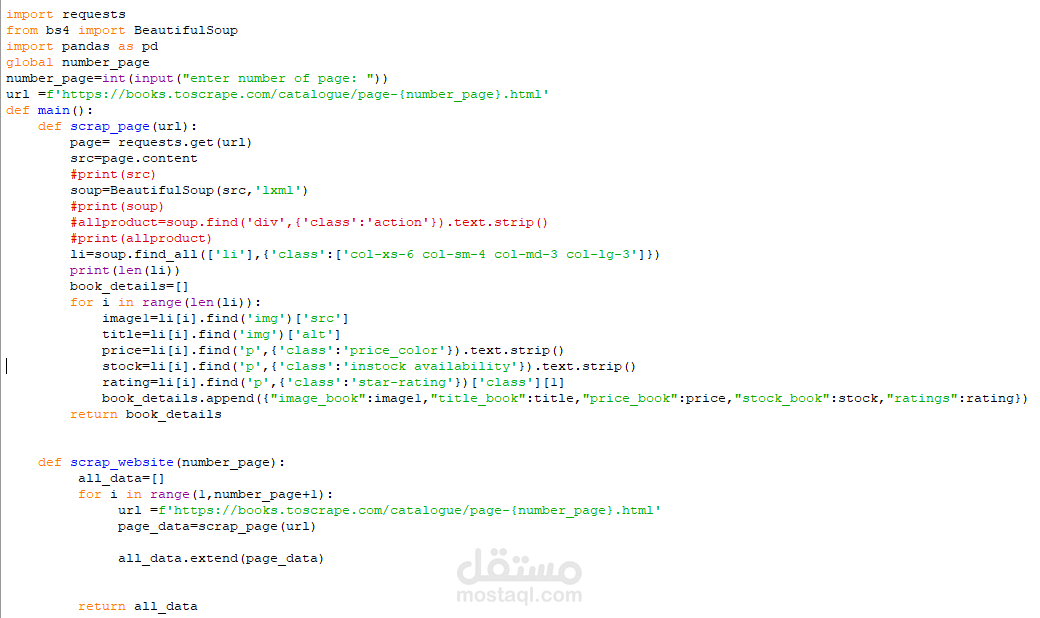
This Python script is designed to scrape book data from a website (books.toscrape.com) and collect details such as the book's image URL, title, price, stock status, and rating. The script uses the requests library to fetch webpage content and BeautifulSoup from the bs4 library to parse and extract specific elements from the HTML. Finally, it organizes the scraped data into a pandas DataFrame and saves it as a CSV file for analysis or storage.