تحليل اراء عملاء amazon
تفاصيل العمل

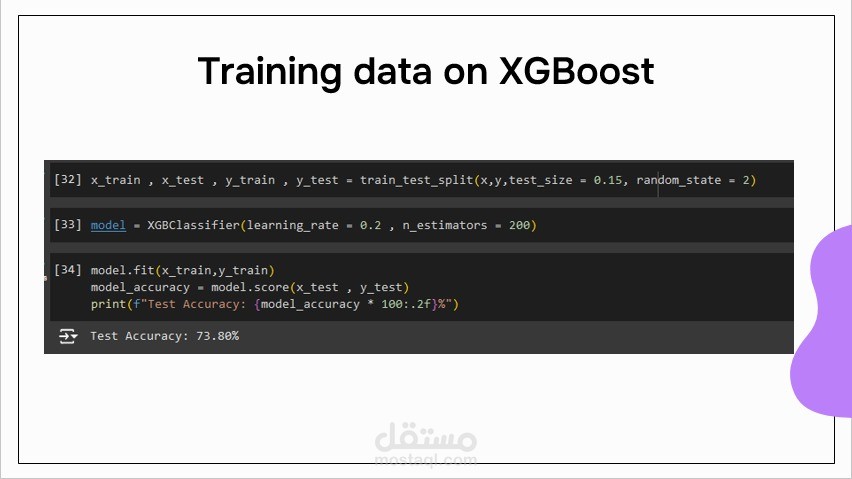
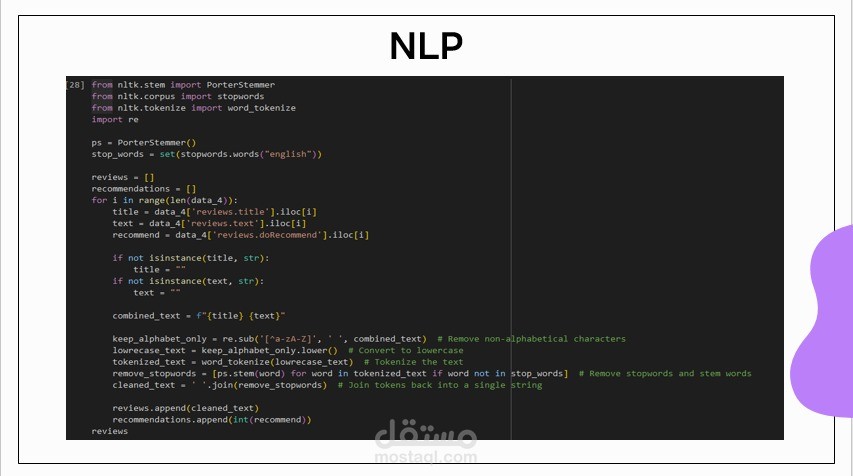
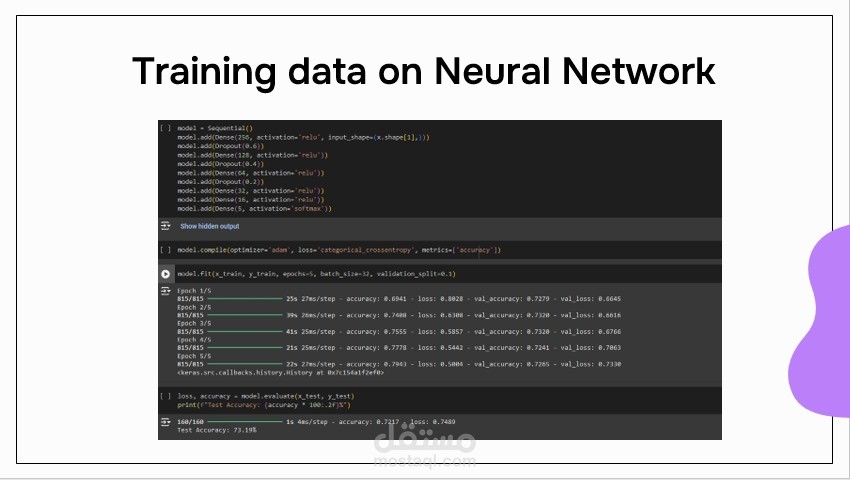

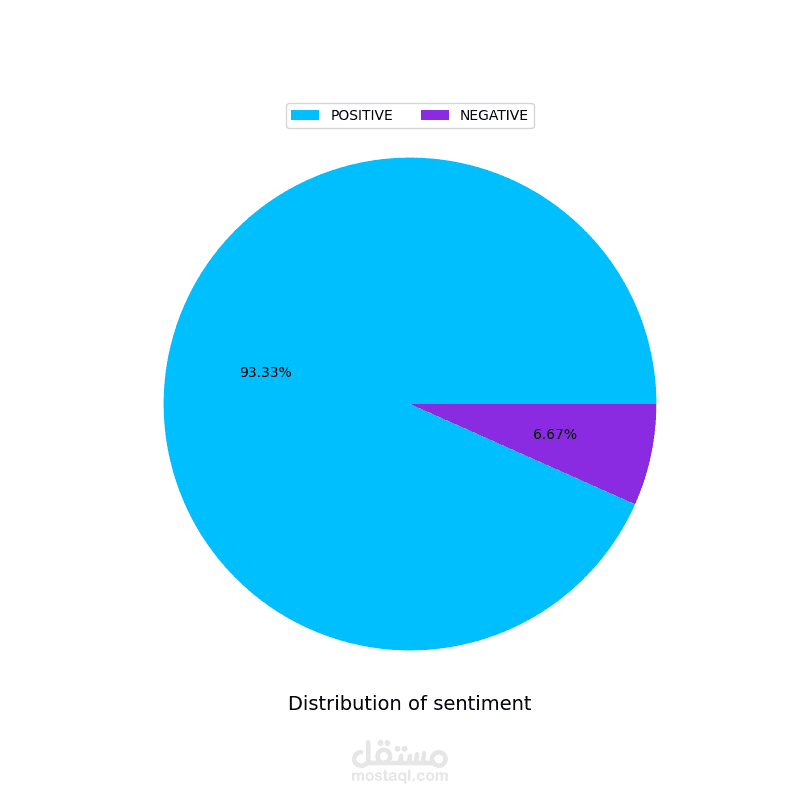
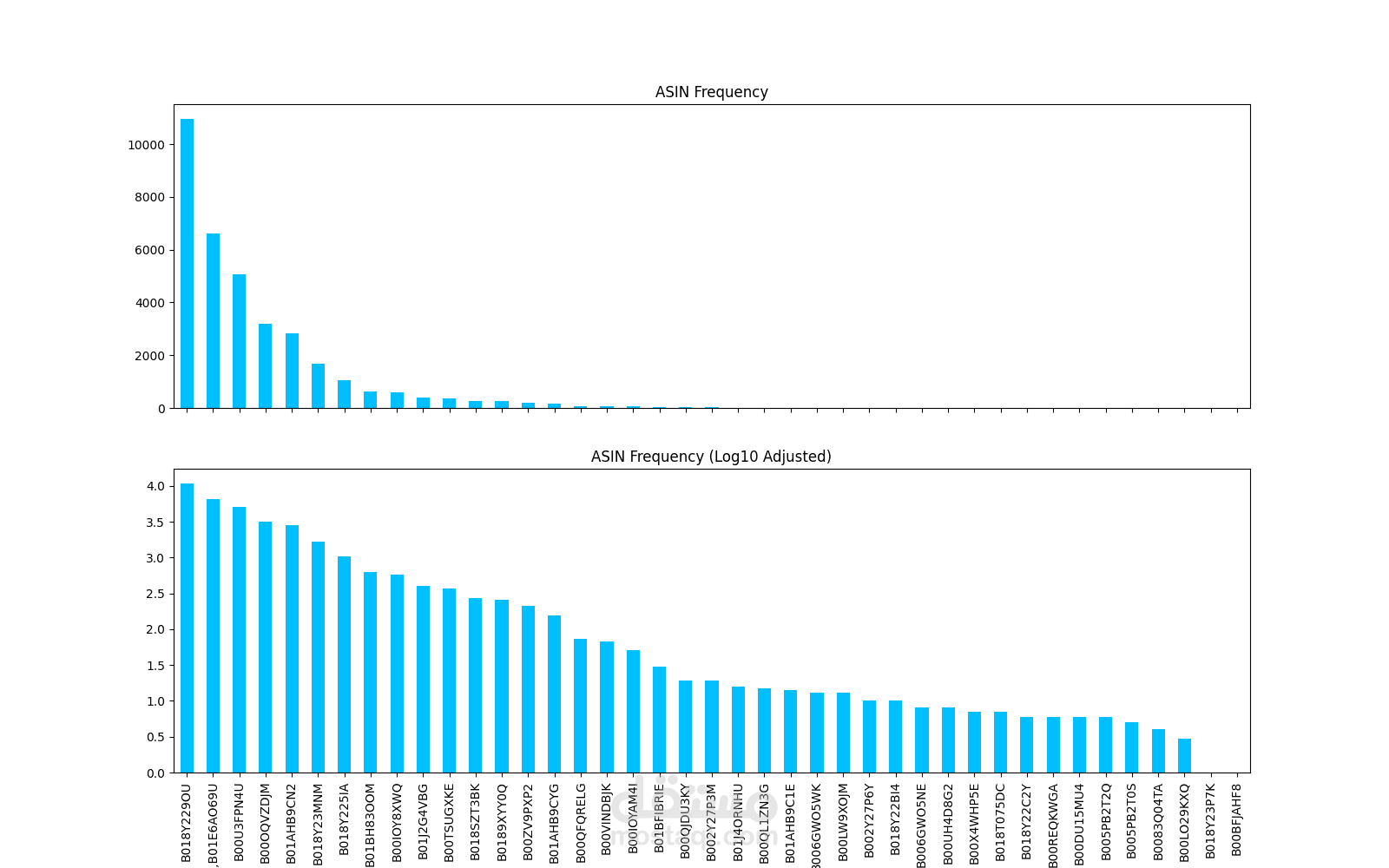
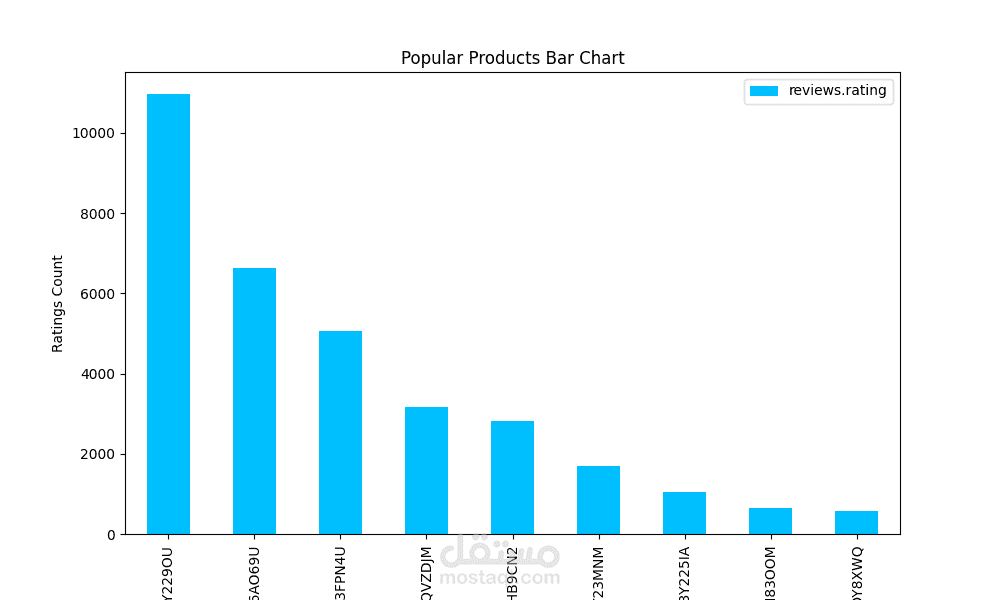

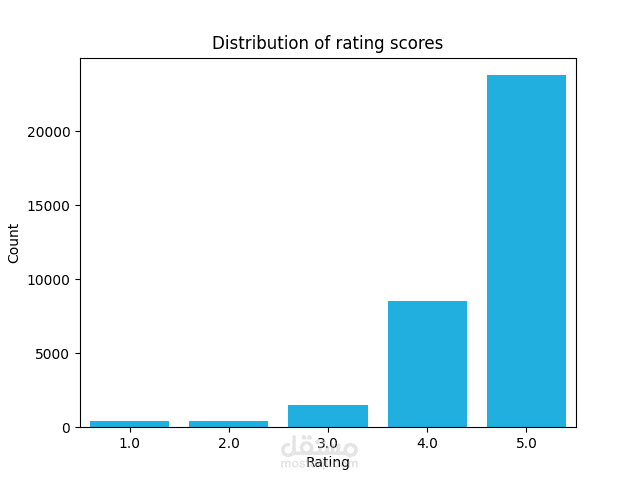
قمت بإجراء معالجة البيانات وتحليلها لاكتشاف الأنماط وتحديد المنتجات ذات التقييمات العالية والمنخفضة، بالإضافة إلى استخراج رؤى حول جودة المنتجات. حققت دقة تدريب بلغت 82٪ باستخدام نموذج معالجة اللغة الطبيعية (NLP) يعتمد على خوارزميات XGBoost وNaive Bayes وKeras للتنبؤ بتقييمات المراجعات وتقديم توصيات مخصصة للمنتجات بناءً على محتوى وعناوين المراجعات.
بطاقة العمل
| اسم المستقل | محمد ع. |
| عدد الإعجابات | 0 |
| عدد المشاهدات | 3 |
| تاريخ الإضافة | |
| تاريخ الإنجاز |