التنبؤ بسعر الماس
تفاصيل العمل
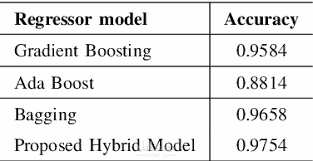
خطوات مسابقة الماس:
- تهدف هذه الوثيقة إلى التركيز على الخطوات الرئيسية التي أدت إلى النتيجة النهائية، بالإضافة إلى جميع الأساليب الإضافية التي تم تجربتها طوال عمر المشروع.
EDA:
- تم حذف عمود المعرف لأنه لا يعطي أي معلومات أساسية للبيانات.
- بعد التحقق من القيم الفارغة، لم يتم العثور على أي منها.
- تم العثور على 97 قيمة مكررة، وتم حذفها.
- يبدو أن عمود السعر هو العمود الذي يحتوي على معظم القيم المتطرفة، وهو ما كان من الصعب التعامل معه لأنه ليس من الفعّال استبدالها أو تقليصها حيث إن تباين الأسعار ضروري في السوق والنموذج لإصدار أسعار أعلى موجود.
- تم إنشاء خريطة حرارية للارتباط لفهم كيفية ارتباط الأعمدة بشكل أكبر
- أعمدة x وy وz مرتبطة بشكل كبير، ويمكننا أن نجد أن القيراط له أيضًا قيمة ارتباط عالية بالأسعار
رؤى التصور:
- أثناء استكشاف الانحراف، بدا أن أعمدة x وy وz والقيراط منحرفة إلى اليمين مما يعني أن المتوسط أكبر من الوسيط، ولهذا السبب تظهر الكثير من القيم المتطرفة في هذه الأعمدة
- بينما يبدو أن أعمدة العمق والجدول منحرفة قليلاً إلى اليسار
- يبدو أن القطع المثالي هو الأكثر شيوعًا ويتم شراؤه بشكل متكرر
- تعد وضوح Sl1 وVs2 الأكثر شيوعًا وهما ليسا أعلى وضوحًا ولا يمكن اكتشافهما بسهولة
feature engineering:
- لتحقيق تقليل الأبعاد وإنشاء مجموعة بيانات أكثر إفادة، يتم دمج أعمدة x وy وz في عمود الحجم.
- يتم أيضًا إنشاء عمود الكثافة من حاصل ضرب القيراط والحجم لتوفير المزيد من المعلومات وإظهار تأثير التفاعلات على النموذج.
- أظهر استكشاف ارتباط العمود الرقمي بعمود السعر أن القيراط هو العمود الأعلى ارتباطًا بينما العمق هو الأقل ارتباطًا مما سيساعدنا لاحقًا في اتخاذ قرار تقليل الميزة.
- خط أنابيب التحويل الكامل:
- يتم إنشاء خط أنابيب المعالجة المسبقة بفئتين مخصصتين للمحول.
- يتم استخدام مشفر التسمية للأعمدة التصنيفية لتحويل البيانات التصنيفية إلى تنسيق رقمي يمكن لخوارزميات التعلم الآلي معالجته، على الرغم من أن المشفر الساخن كان خيارًا، إلا أن مشفر التسمية يعمل جيدًا للبيانات الترتيبية.
- تم استخدام مقياس قوي للأعمدة العددية لأنه يمكنه التعامل مع القيم المتطرفة بشكل جيد لأنه يقلل من تأثيره باستخدام الوسيط وIQR بدلاً من المتوسط والانحراف المعياري في المقياس القياسي.
تنفيذ النموذج:
- لقد جربنا العديد من النماذج المختلفة للحصول على أدنى درجة RMSE.
- تم استخدام التحقق المتبادل للموافقة على النتيجة:
>> سيتم ذكر درجات النموذج:
1- نموذج SVM: درجة RMSE 2749.42
2- نموذج Decision Tree: درجة RMSE 739.696
3- نموذج Random Forest : درجة RMSE 556.09
4- مصنف التصويت مع (الغابة العشوائية المتدرجة - التلال): درجة RMSE 736
5- نموذج الشبكة العصبية: بدرجة RMSE 29641496
6- نموذج Linear Regression: درجة RMSE 1196.2
الخطوات التي تم إجراؤها بعد تنفيذ النموذج:
- كان من الواضح أن شجرة الغابة العشوائية بدت وكأنها تعطي النتيجة الأكثر كفاءة ولكنها ليست الأفضل، لذلك تم إجراء عدة محاولات لمحاولة تقليل النتيجة.
- اختيار الميزة من خلال إزالة الميزات ذات الارتباط الأقل بالسعر ولكن هذا لم يساعد كثيرًا مع زيادة درجة الخطأ.
- بعد التعرف على أهمية الميزة بعد ضبط المعلمات الفائقة، تم إنشاء إطار بيانات جديد يحتوي فقط على ميزات مهمة بأعلى درجة أهمية وتمت مواجهته من خلال الخطوات السابقة مرة أخرى، ولكن هذا أظهر أيضًا درجة خطأ أعلى.
- في هذه المرحلة، احتجنا إلى الرجوع خطوة إلى الوراء والتحقيق في مرحلة معالجة البيانات، لذا كان أول شيء جربناه هو تغيير طرق التدرج، ولكن هذا لم ينجح أيضًا.
- لم يكن التعامل مع القيم المتطرفة باستخدام طريقة الحد الأقصى باستخدام IQR ناجحًا لأنه بدا أنه يزيد من سوء التنبؤ بالنموذج ويتسبب في الإفراط في التجهيز.
- استنتجنا أن أي تغيير في البيانات الأصلية أو التشذيب لم يكن الخيار الأفضل.
ضبط المعلمات الفائقة:
- في البداية، استخدمنا GridSearchcv العادي الذي أظهر درجة 557
- تم استخدام BayesSearchcv بعد ذلك ولكنه أعطى خطأ أعلى
- بالعودة إلى GridSearchcv، جربنا المعلمات الممتدة، ولكن هذا زاد من وقت التشغيل بشكل كبير.
- تم استخدام خوارزمية التعزيز التي تستخدم شجرة القرار كمتعلم ضعيف وتدريبهم بشكل متسلسل مما يساعد في تحسين النتيجة للوصول إلى أقل درجة لدينا
ملفات مرفقة
بطاقة العمل
| اسم المستقل | Mohamed A. |
| عدد الإعجابات | 0 |
| عدد المشاهدات | 3 |
| تاريخ الإضافة | |
| تاريخ الإنجاز |