توقع مرض باركنسون باستخدام تعلم الآلة
تفاصيل العمل

مراحل التنفيذ:
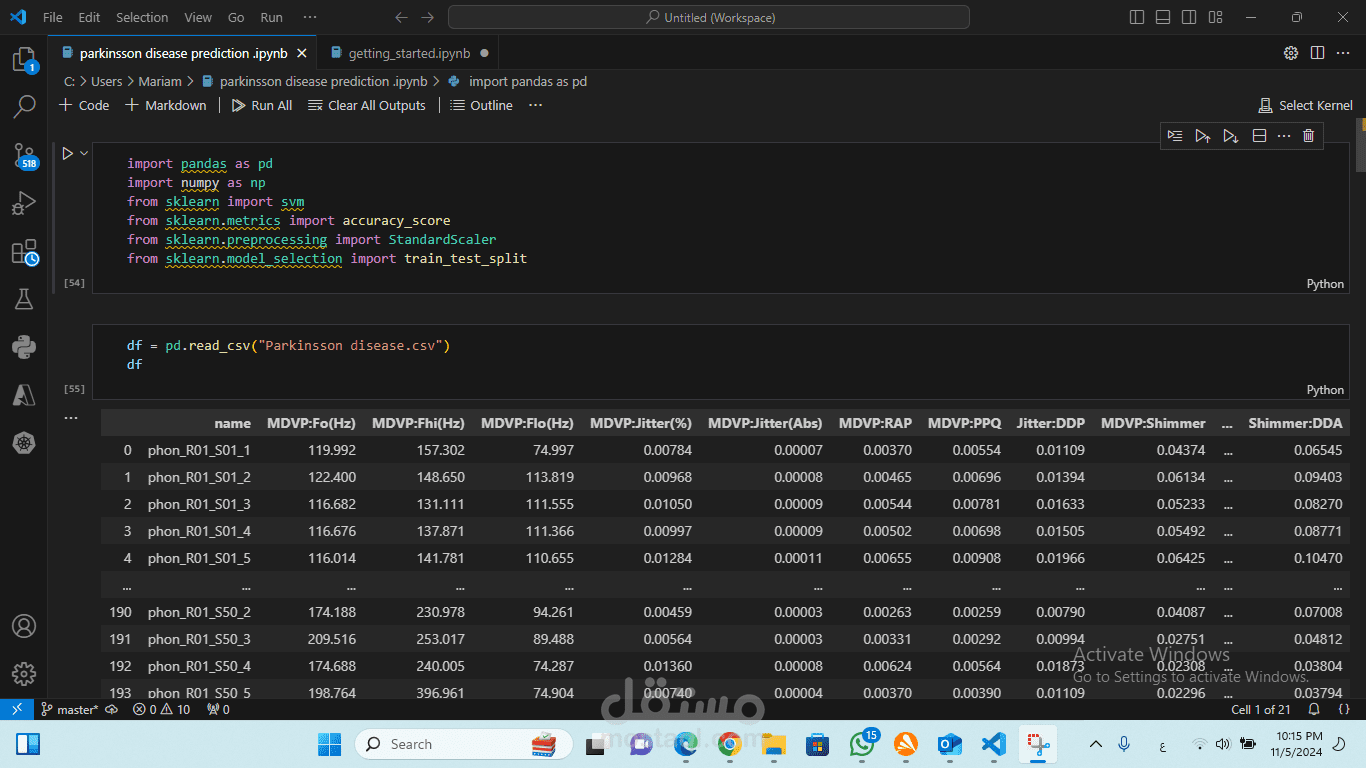
جمع البيانات: الحصول على مجموعات البيانات من مصادر موثوقة مثل UCI Machine Learning Repository، والتي قد تتضمن مقاييس صوتية للأفراد.
معالجة البيانات:
تنظيف البيانات من خلال التعامل مع القيم المفقودة أو البيانات الشاذة.
تطبيع أو توسيع نطاق البيانات باستخدام طرق مثل MinMaxScaler لضمان التجانس بين الميزات.
اختيار الميزات: تحديد الميزات الأكثر أهمية باستخدام تقنيات مثل اختيار الميزات العكسي (RFE) أو مصفوفات الارتباط لتحسين أداء النموذج.
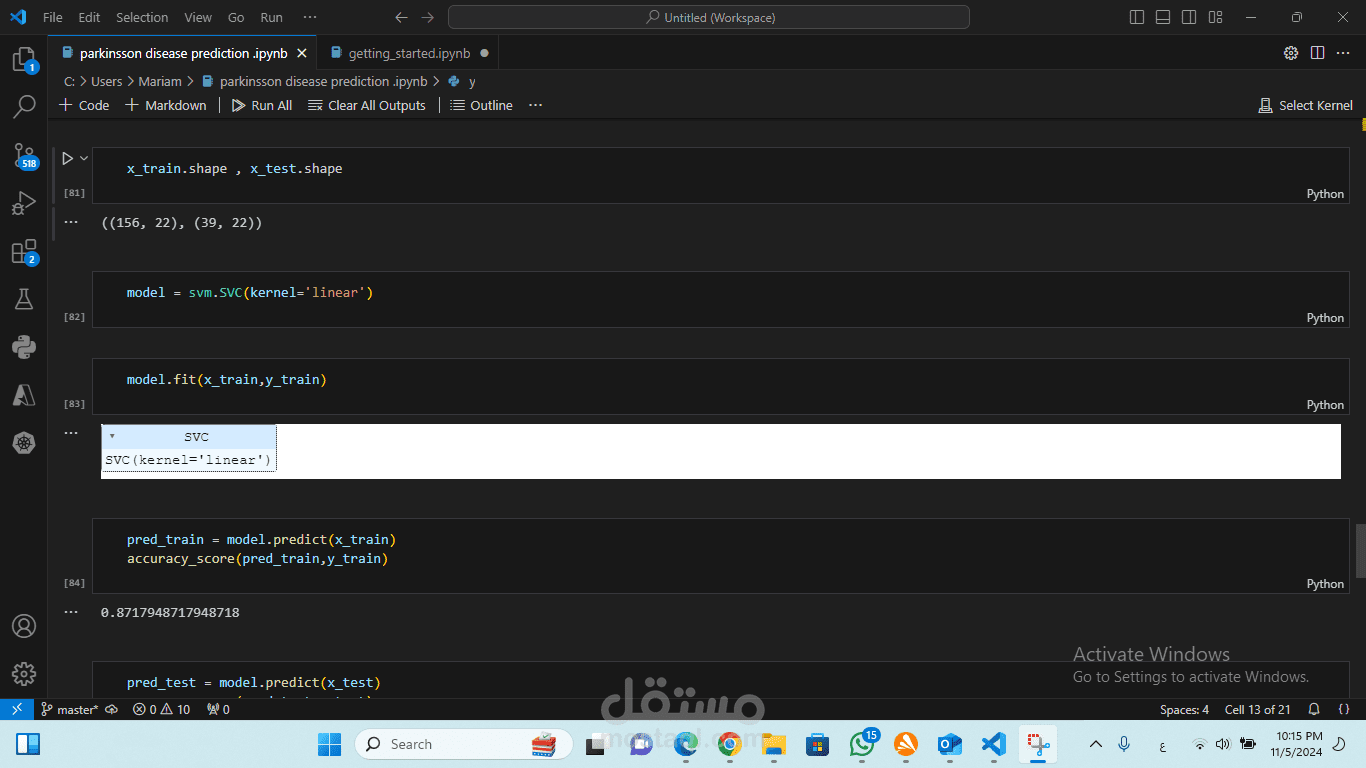
بناء النموذج:
استخدام خوارزميات مثل SVM أو الغابة العشوائية (Random Forest) أو XGBoost.
تقسيم البيانات إلى مجموعات للتدريب والاختبار (مثل 80/20).
تدريب النموذج باستخدام مكتبات Python مثل Scikit-learn.
تقييم النموذج:
تقييم النموذج باستخدام مقاييس مثل الدقة (Accuracy)، والدقة النوعية (Precision)، والاسترجاع (Recall)، وF1-score.
استخدام التحقق المتقاطع (Cross-validation) للتأكد من قوة النموذج.
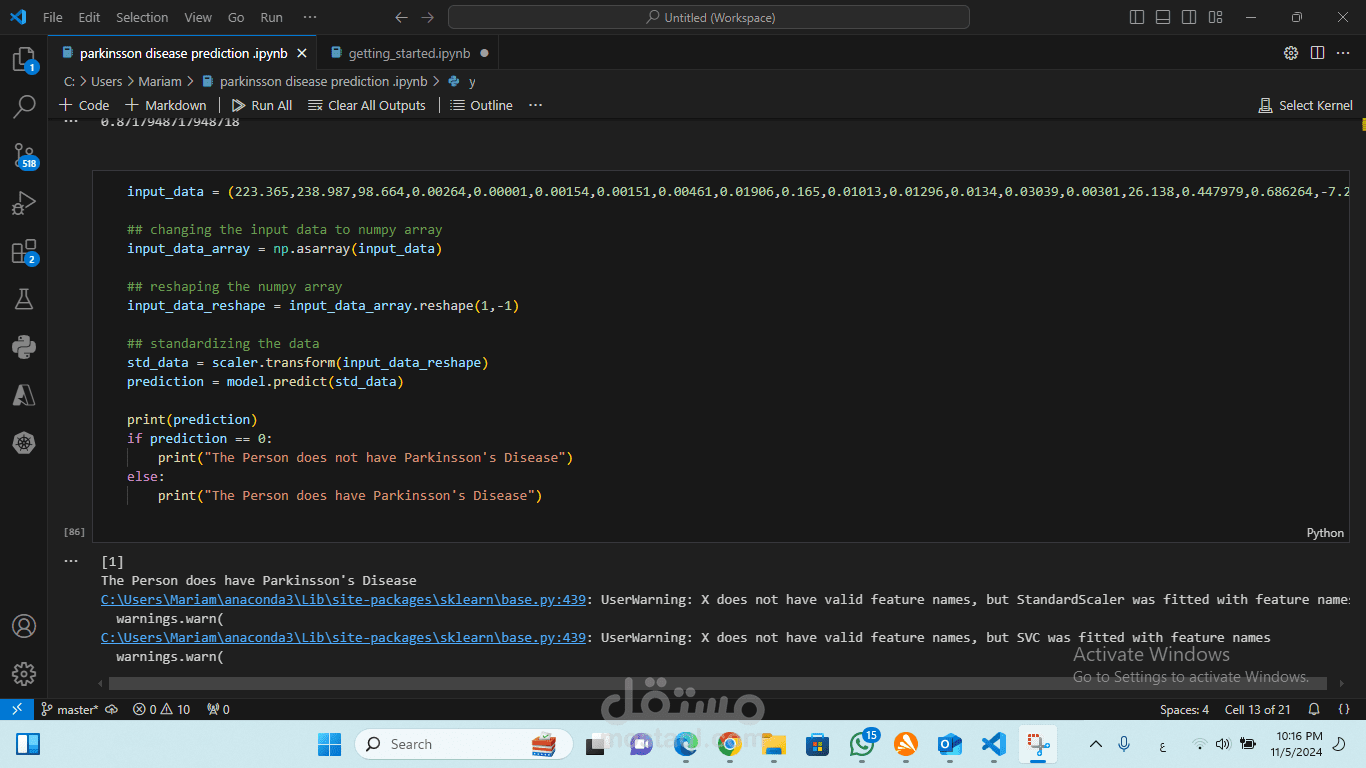
نشر النموذج:
إنشاء واجهة مستخدم سهلة الاستخدام باستخدام Flask أو FastAPI للتنبؤ الفوري.
التكامل مع أدوات مثل Docker للحاويات في حال كان النشر على منصات سحابية (مثل Azure أو AWS) مطلوبًا.
الأدوات والتقنيات المستخدمة:
لغة البرمجة: Python
المكتبات: Pandas، NumPy، Scikit-learn، Matplotlib، Seaborn، XGBoost
بيئة البرمجة: Jupyter Notebook، VS Code
نشر النموذج: Flask أو FastAPI
أدوات إضافية: Docker للحاويات، Git للتحكم في الإصدارات
بطاقة العمل
| اسم المستقل | Maryam M. |
| عدد الإعجابات | 0 |
| عدد المشاهدات | 2 |
| تاريخ الإضافة |