كشف الرسائل العشوائية باستخدام NLP
تفاصيل العمل

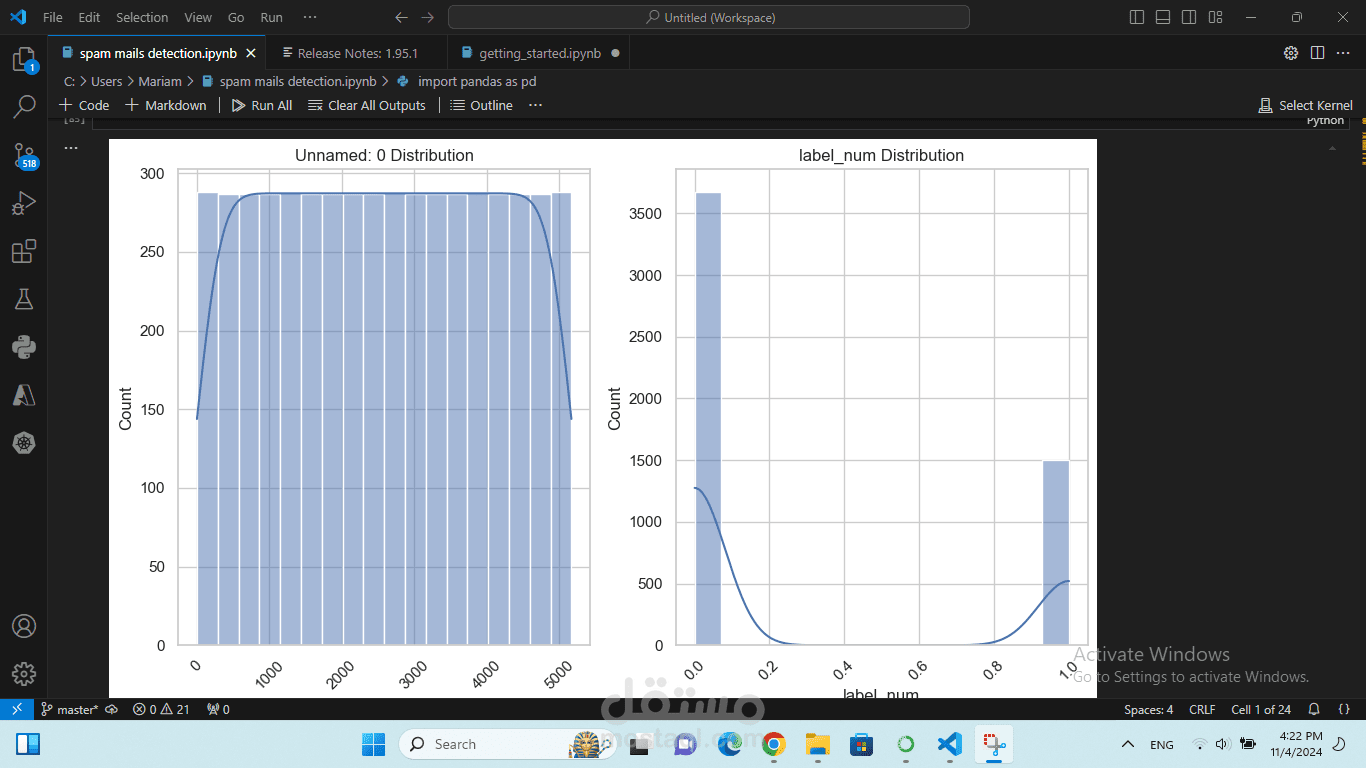
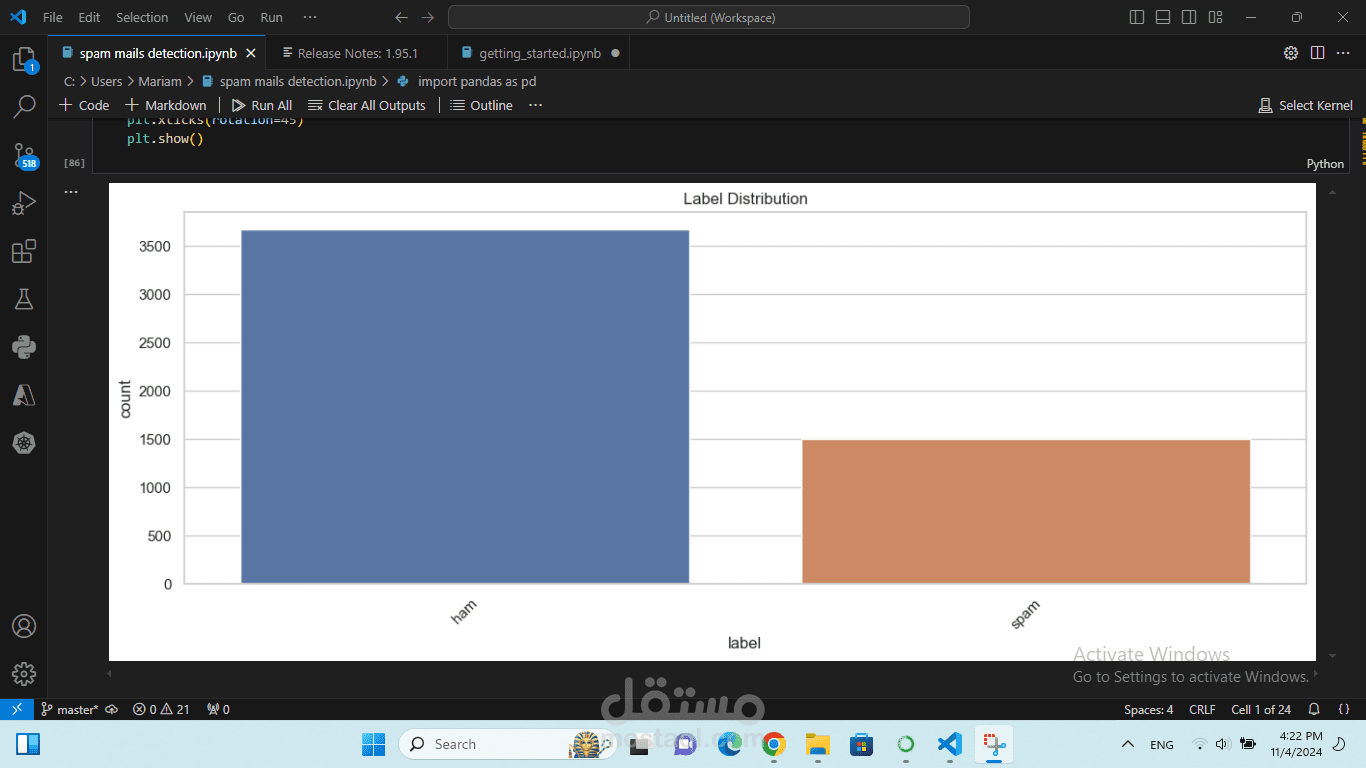
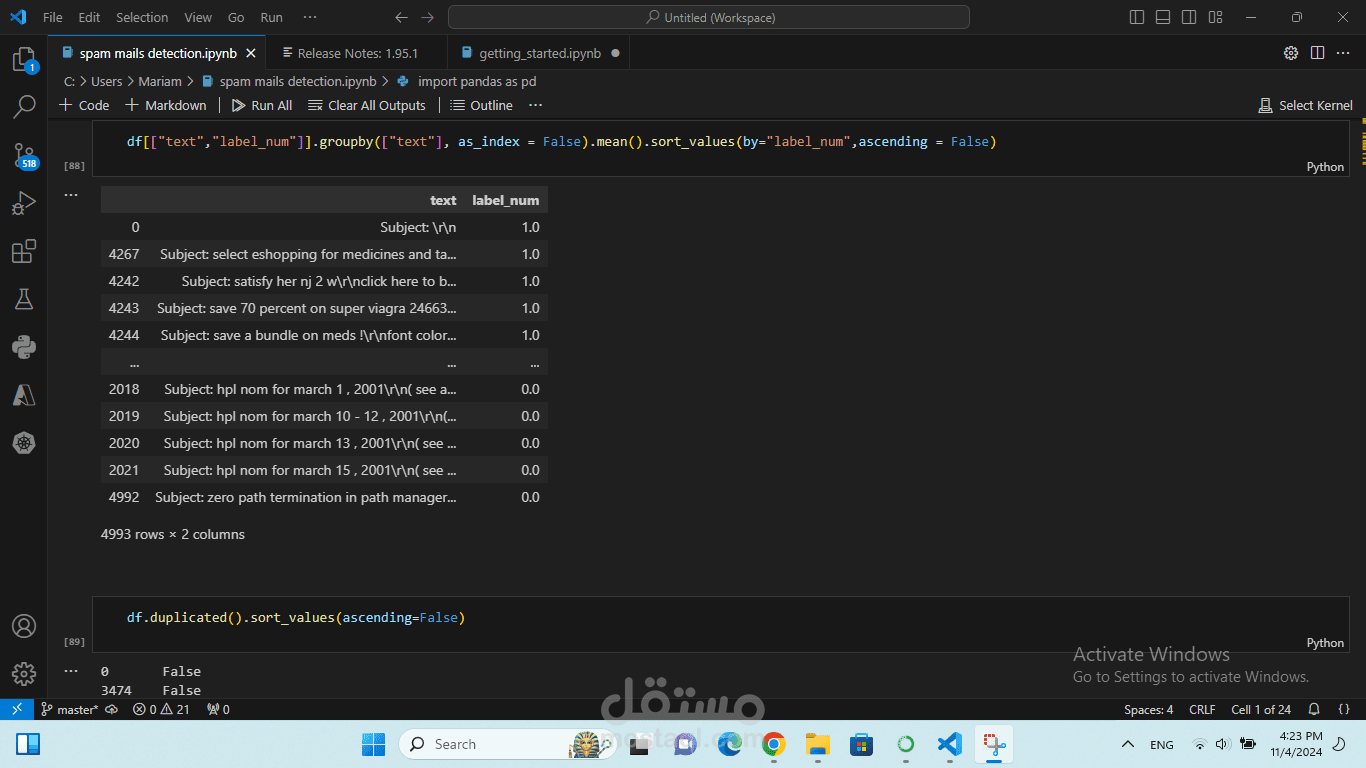
المراحل:
جمع البيانات: البحث عن مجموعات بيانات مفتوحة المصدر تحتوي على رسائل مصنفة مسبقًا (مثل "هام" و"سبام").
تنظيف البيانات: استخدام تقنيات معالجة النصوص لتنظيف البيانات، مثل إزالة التكرار والكلمات غير المفيدة.
تحويل النصوص: استخدام أدوات مثل TF-IDF أو Word2Vec لتحويل النصوص إلى صيغ عددية يمكن للنموذج فهمها.
بناء النموذج: اختيار خوارزمية مناسبة، مثل Naive Bayes أو SVM، وتدريب النموذج باستخدام مكتبات مثل Scikit-learn أو TensorFlow.
تقييم الأداء: استخدام معايير مثل دقة النموذج أو F1-score لتقييم الأداء وتحسين النموذج حسب الحاجة.
النشر: بناء واجهة مستخدم بسيطة باستخدام Flask أو FastAPI لتمكين المستخدم من فحص الرسائل.
الأدوات المستخدمة:
لغة البرمجة: Python
مكتبات: Pandas، Scikit-learn، NLTK، TensorFlow
بيئة البرمجة: Jupyter Notebook أو VS Code
واجهة المستخدم: Flask أو FastAPI
إذا كنت بحاجة لتوصيف المزيد من المشاريع أو إضافة تفاصيل أخرى، فلا تتردد في طلب ذلك!