تحليل بيانات الناجين من سفينة تايتنك
تفاصيل العمل
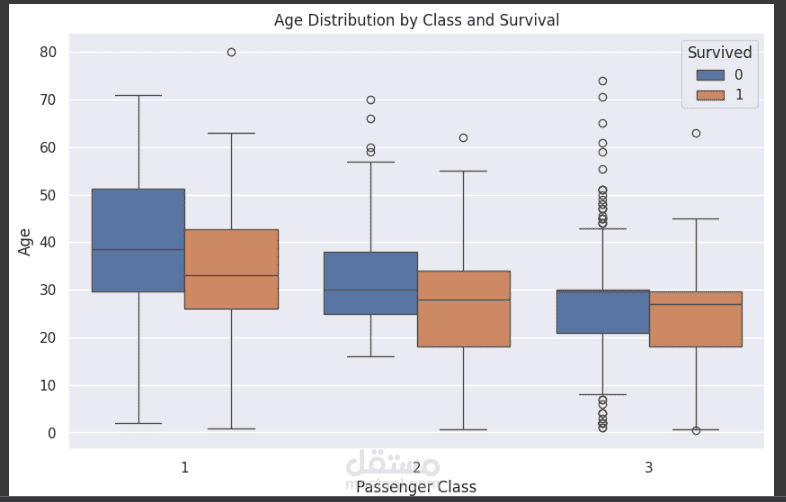
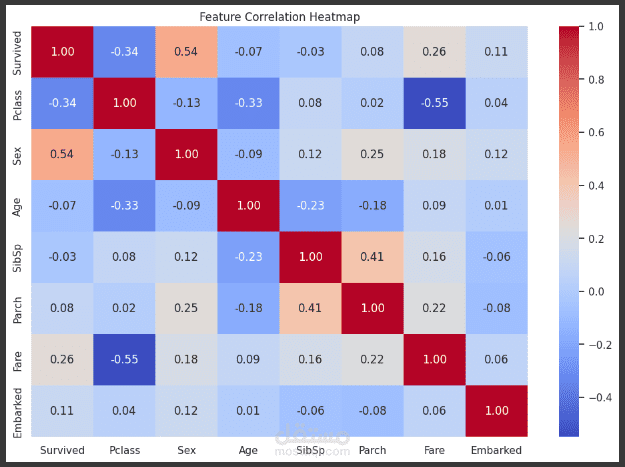
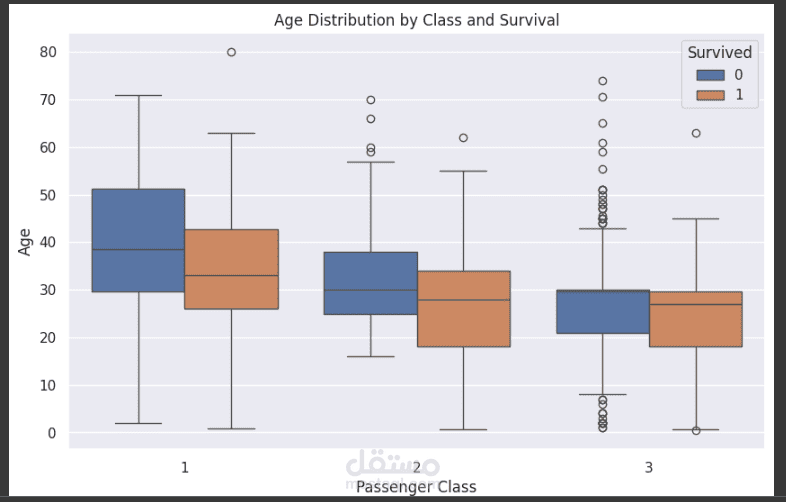
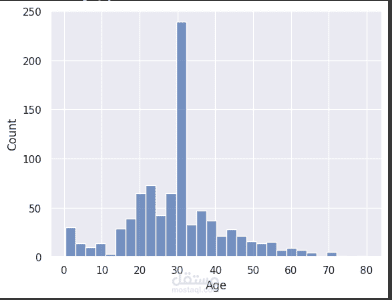
يهدف نموذج Titanic إلى التنبؤ ببقاء الركاب على قيد الحياة بعد غرق السفينة، بالاعتماد على مجموعة من الخصائص مثل العمر، النوع، الدرجة، وعدد أفراد العائلة المرافقين. تُستخدم هذه المجموعة الشهيرة من البيانات لتعليم وتدريب خوارزميات تعلم الآلة على التنبؤ بالبقاء بناءً على العوامل المتوفرة.
الخطوات الرئيسية:
1- معالجة البيانات: تنظيف البيانات بالتعامل مع القيم الناقصة، مثل ملء الأعمار غير المحددة أو استبدالها بقيمة متوسطة، والتعامل مع الخصائص النصية بتحويلها إلى أرقام أو فئات.
2- اختيار الميزات: تحليل أهمية كل ميزة والتأكد من تركيز النموذج على الميزات الأكثر تأثيرًا في التنبؤ مثل النوع والدرجة والعمر.
3- التشفير: تحويل البيانات الفئوية (مثل النوع والدرجة) إلى قيم رقمية باستخدام تقنيات مثل One-Hot Encoding لجعلها صالحة للتدريب.
4- تقسيم البيانات: تقسيم البيانات إلى مجموعة تدريبية وأخرى اختبارية لضمان القدرة على تقييم النموذج بشكل موضوعي.
بناء النموذج: تدريب خوارزميات تصنيف مثل الانحدار اللوجستي، شجرة القرار، أو الغابة العشوائية للتنبؤ بمعدل بقاء الركاب بناءً على الخصائص.
5- تقييم النموذج: قياس دقة النموذج باستخدام معايير مثل الدقة والاسترجاع ومعدل الخطأ على مجموعة الاختبار، والتأكد من كفاءة النموذج في التنبؤ ببقاء الركاب.
6- تحسين النموذج: استخدام تقنيات تحسين مثل Grid Search والتدريب التكراري لضبط المعاملات وزيادة كفاءة النموذج.
ملفات مرفقة
بطاقة العمل
| اسم المستقل | احمد ع. |
| عدد الإعجابات | 0 |
| عدد المشاهدات | 32 |
| تاريخ الإضافة | |
| تاريخ الإنجاز |