استخلاص البيانات من الويب
تفاصيل العمل
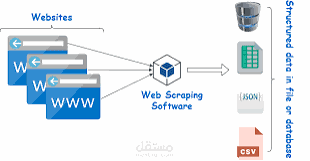
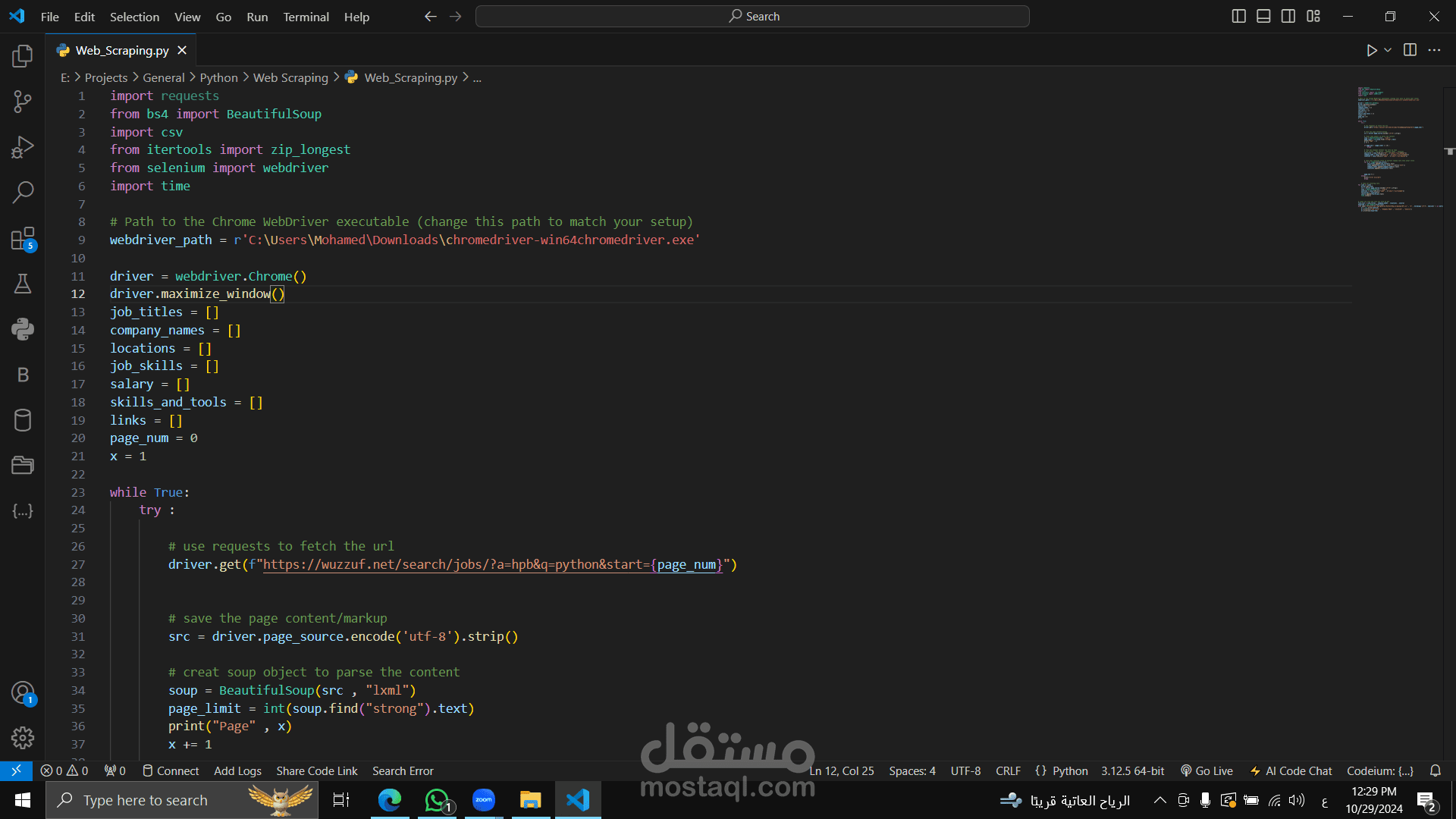
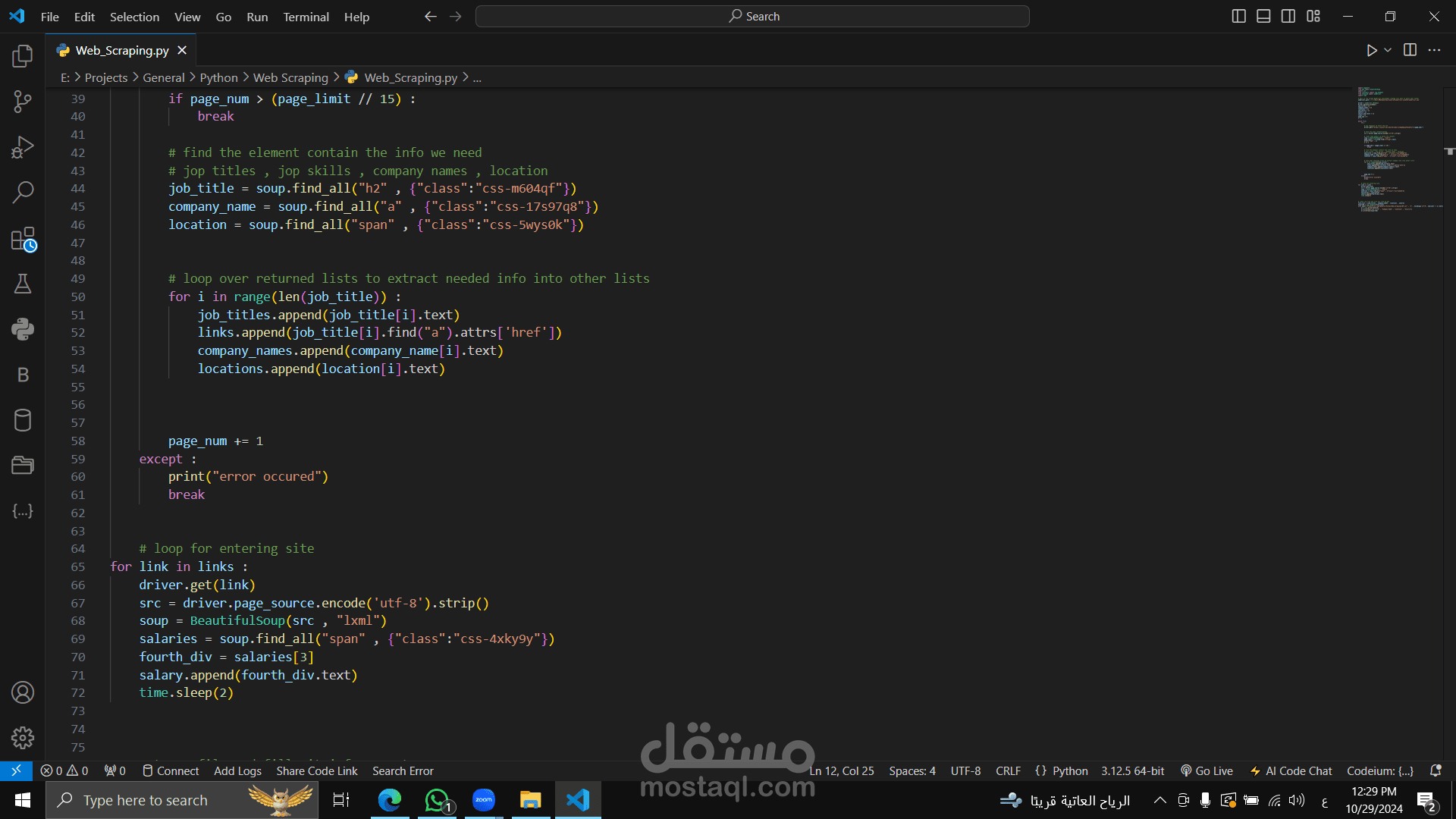
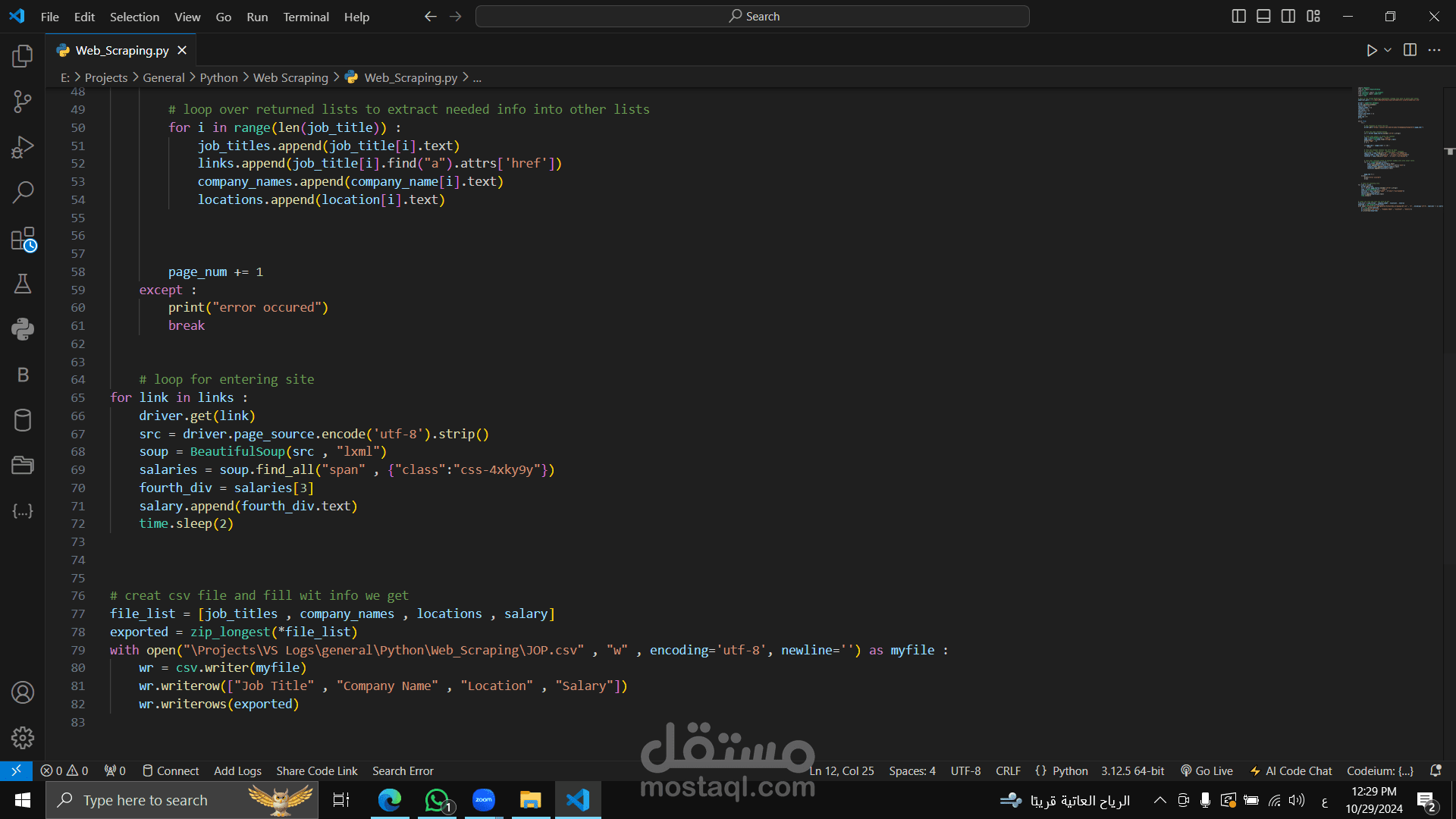

برنامج Python لعملية Web Scraping يقوم بجمع بيانات الوظائف من موقع Wuzzuf باستخدام مكتبة Selenium وBeautifulSoup، والهدف منه تجميع بيانات مثل عناوين الوظائف، أسماء الشركات، المواقع، والرواتب وتصديرها كملف CSV.
الوصف التفصيلي:
المكتبات المستخدمة :
يستعين بمكتبات requests و BeautifulSoup لتحليل صفحات الويب.
يستخدم csv لتخزين البيانات المستخرجة في ملف CSV.
مكتبة selenium للتحكم في المتصفح وجلب البيانات من صفحات متعددة.
تكوين متصفح كروم:
يبدأ بتكوين WebDriver لمتصفح Chrome باستخدام مسار المتصفح المثبت على الجهاز.
البحث وجلب البيانات:
يزور الصفحة الرئيسية للبحث في Wuzzuf، ويبحث عن الوظائف المتعلقة بـ"Python" ويستخدم BeautifulSoup لتحليل الصفحة.
يخزن بيانات مثل: عنوان الوظيفة، اسم الشركة، الموقع، والروابط للوظائف.
التحقق من عدد الصفحات:
يقوم بحساب عدد الصفحات ويستمر في التصفح حتى يصل للصفحة الأخيرة.
زيارة الروابط لجمع بيانات الرواتب:
بعد جمع الروابط، يزور كل رابط للحصول على الراتب من التفاصيل الوظيفية ويضيفه للبيانات.
تصدير البيانات لملف CSV:
ينشئ ملف JOP.csv ويحفظ البيانات في الأعمدة: عنوان الوظيفة، اسم الشركة، الموقع، الراتب.
التعامل مع الأخطاء:
يستخدم try-except للتعامل مع أي خطأ قد يحدث خلال جمع البيانات.
الاستخدام:
يستخدم لتحليل سوق العمل واستكشاف الوظائف المتاحة والتفاصيل المرتبطة بها، وخصوصًا إذا كنت بحاجة للبحث عن معلومات دقيقة من مواقع التوظيف وتخزينها لتحليلها لاحقًا.