نظام التوصية بالافلام
تفاصيل العمل
نظرة عامة:
يغطي هذا المشروع دورة حياة البيانات كاملة، من استخراج بيانات الأفلام إلى نشر نظام توصية فعال. قمنا بتبسيط العملية لضمان توصيات دقيقة للمستخدمين، مع جعل تحليل البيانات سهلاً وسلسًا.
أهم النقاط:
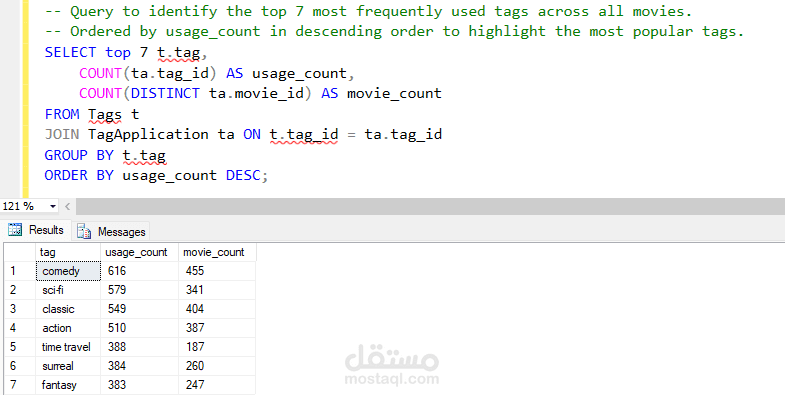
مصادر البيانات: عملنا مع عدة صيغ مثل JSON وCSV وXLSX، مع تحديثات يومية تصل الساعة 1 صباحًا.
الأتمتة: أنشأنا عمليات مؤتمتة لمعالجة البيانات وجدولتها، لضمان تحديثات مستمرة وتدفق العمل دون تدخل يدوي.
تحويل البيانات: قمنا بتوحيد وتنظيم البيانات لتصبح جاهزة للقاعدة، مما يسهل التحليل الشامل.
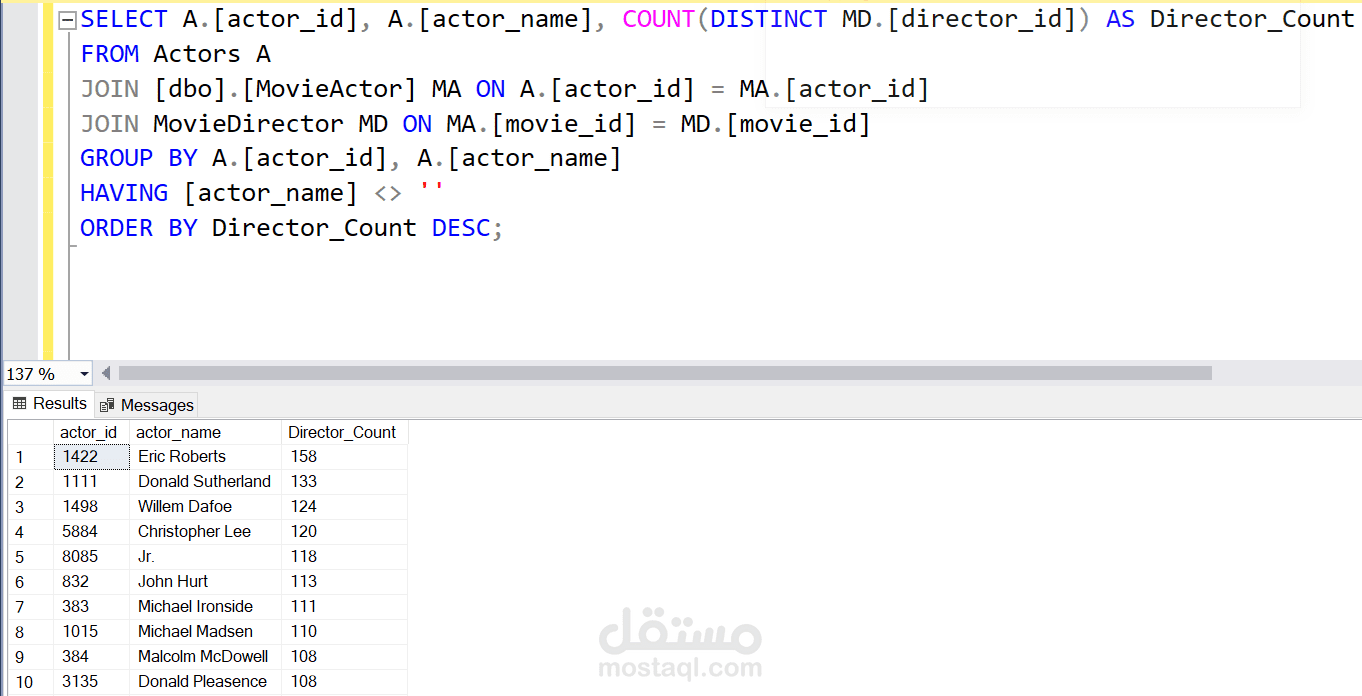
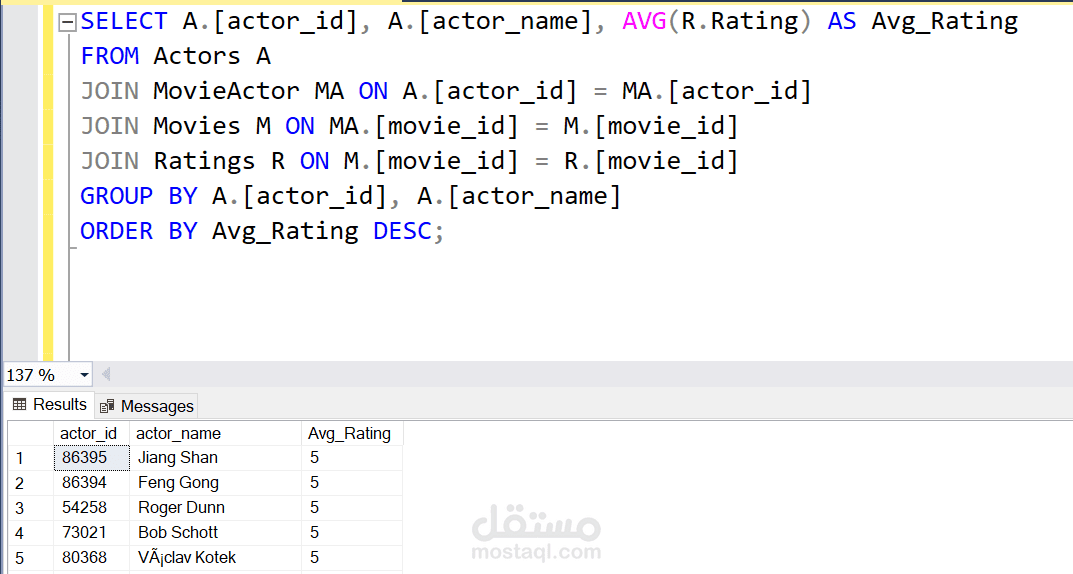
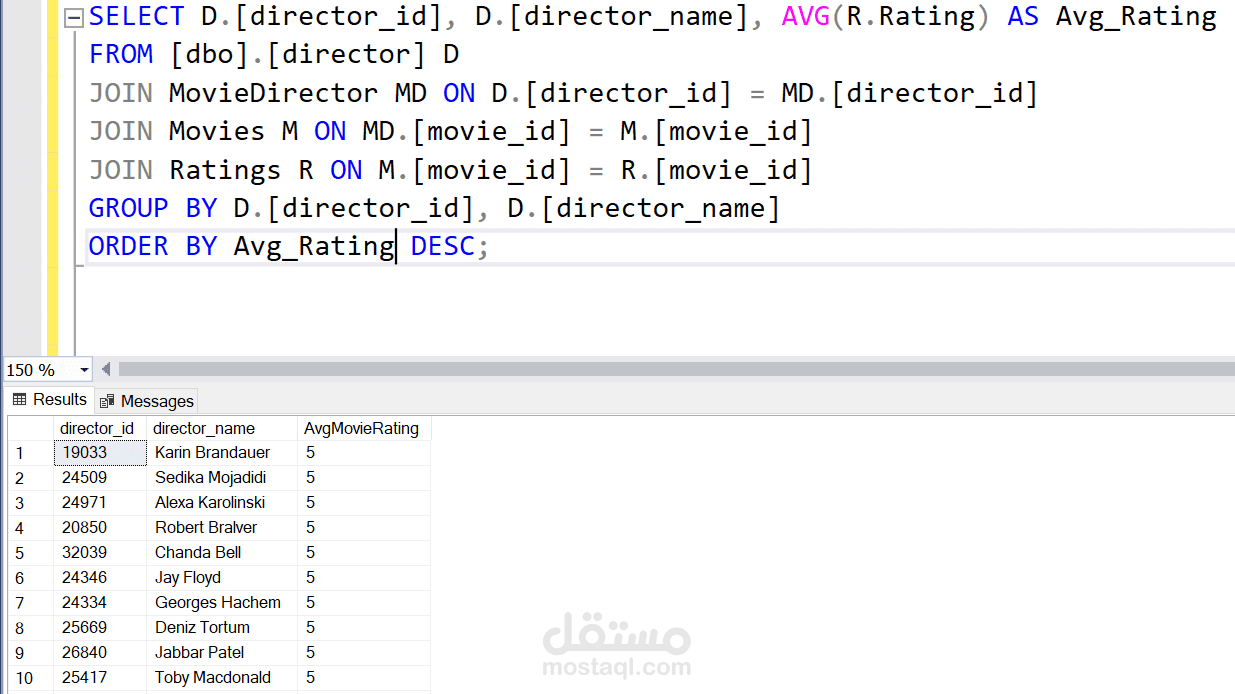
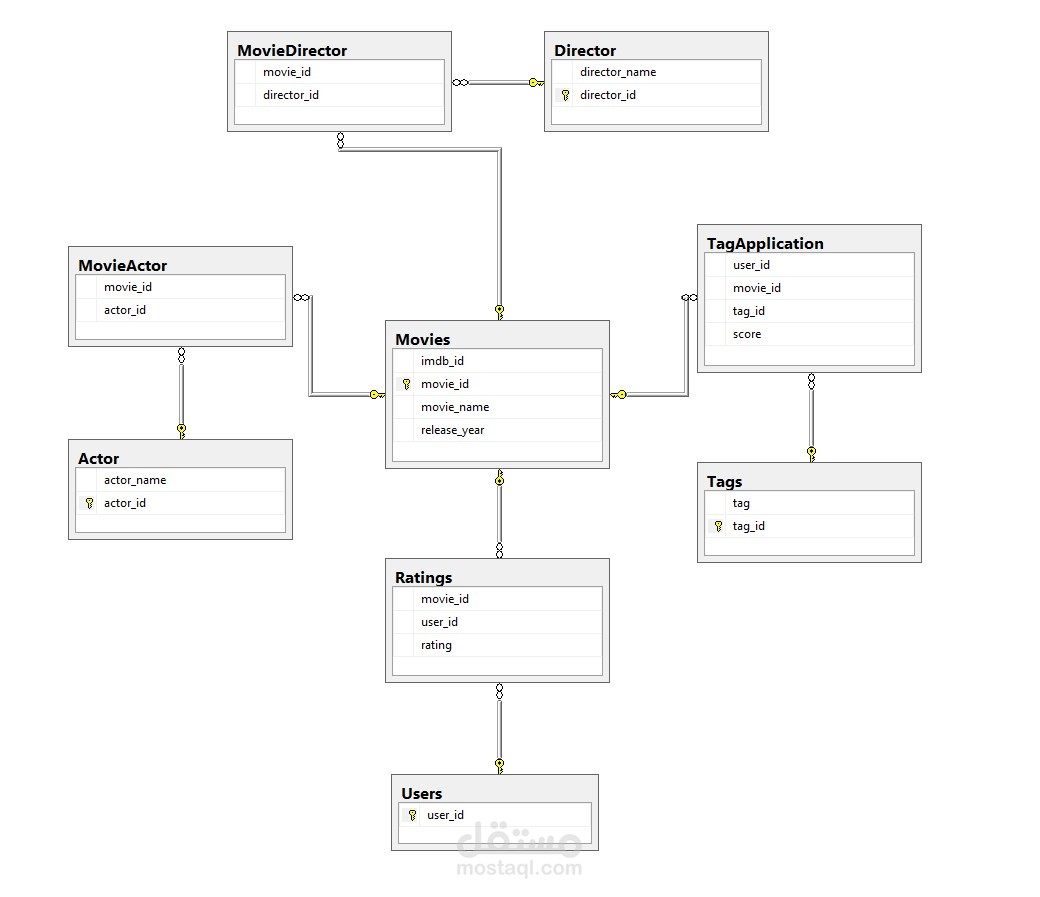
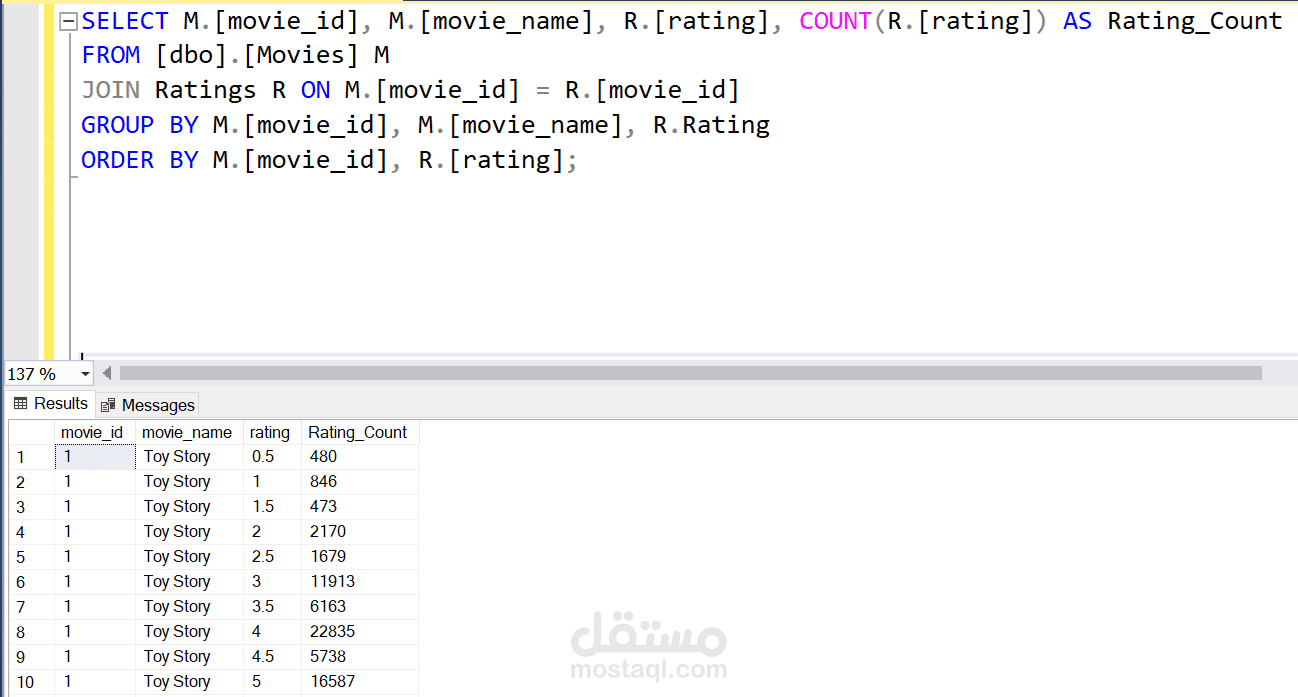
إعداد قاعدة البيانات: تُخزن البيانات المنظمة باستخدام استعلامات SQL مضبوطة ونماذج منظمة لتسهيل الوصول إليها.
مستودع البيانات: باستخدام نمط النجمة (Star Schema)، دمجنا البيانات في مستودع للتمكن من تحليلات متقدمة.
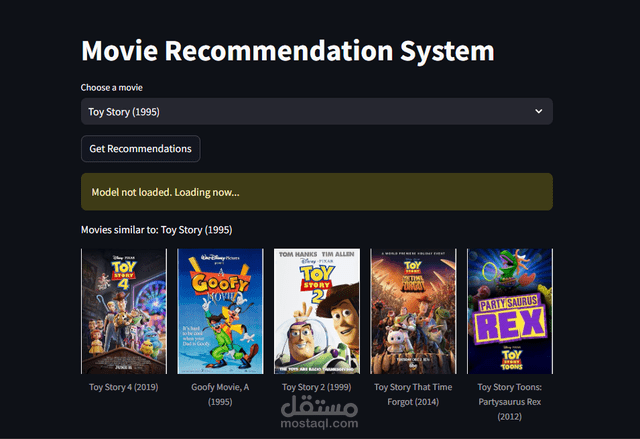
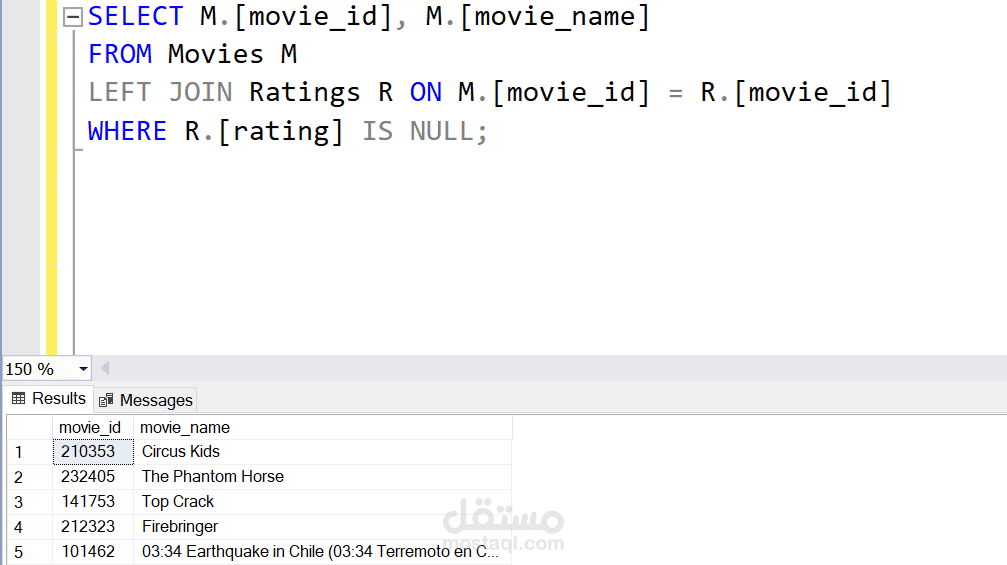
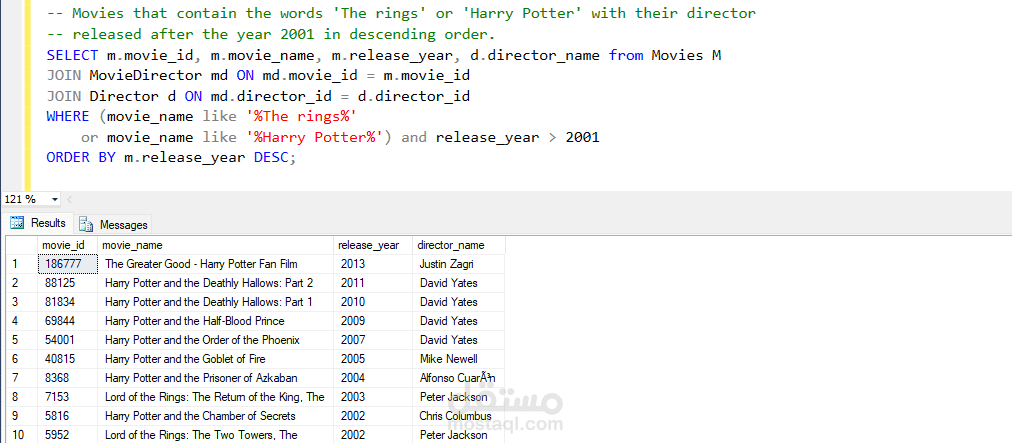
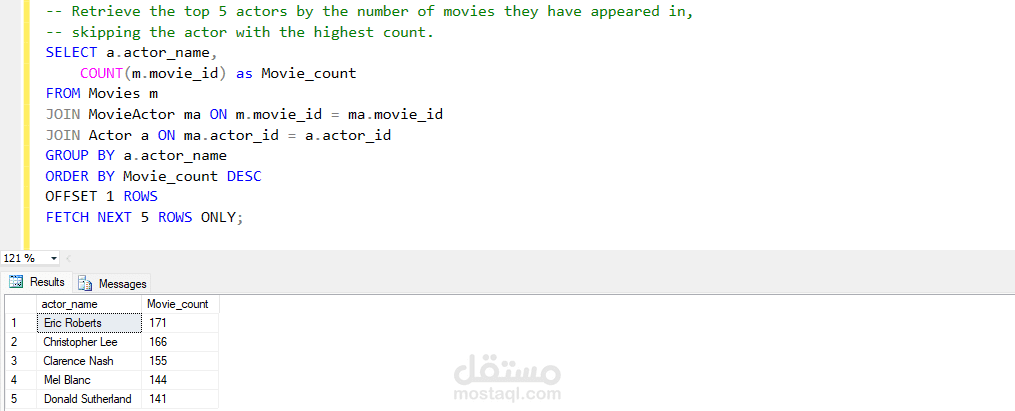
نموذج التوصية: أنشأنا نظام توصية يعتمد على البيانات المحولة، يتيح للمستخدمين الحصول على اقتراحات أفلام مخصصة.
واجهة برمجة التطبيقات (API): طوّرنا API لتسهيل الوصول إلى نموذج التوصيات لدينا من مصادر خارجية.
التقنيات المستخدمة:
التعامل مع البيانات: SQL، SSIS، Python، Pandas، SQLAlchemy
نظام التوصيات: FastAPI، Faiss، Sentence Transformers
متابعة النماذج: MLflow
الأتمتة: Bash، Docker
واجهة المستخدم: Streamlit
ملفات مرفقة
بطاقة العمل
| اسم المستقل | Shahd H. |
| عدد الإعجابات | 0 |
| عدد المشاهدات | 1 |
| تاريخ الإضافة | |
| تاريخ الإنجاز |