مشروع: استخراج البيانات من موقع XPEL باستخدام Selenium وPython
تفاصيل العمل
الوصف العام:
في هذا المشروع، قمت بتطوير أداة برمجية متقدمة لاستخراج البيانات (Web Scraping) من موقع XPEL باستخدام تقنيات Selenium وPython. الهدف من المشروع كان جمع المعلومات المتعلقة بخيارات الحماية من الطلاء للسيارات في مناطق جغرافية معينة مثل الولايات المتحدة وكندا وأوروبا. تم تطوير النظام لتصفح الفلاتر المتعددة على الموقع الإلكتروني واختيار جميع الخيارات المتاحة بشكل ديناميكي ومن ثم حفظ هذه البيانات في ملفات CSV، مع التأكد من أن العملية تعمل بكفاءة وموثوقية.
المميزات الأساسية للمشروع:
التصفح الآلي للموقع:
قمت باستخدام مكتبة Selenium للتحكم في متصفح الويب واختيار الخيارات المناسبة من القوائم المنسدلة في موقع XPEL.
يدير النظام التعامل مع مجموعة من الفلاتر، مثل: نوع السيارة، سنة الإنتاج، الشركة المصنعة (Make)، الطراز (Model)، النماذج الفرعية (Submodel)، والسلاسل (Series).
التعامل مع الأخطاء وتحسين الاستقرار:
قمت ببناء نظام إعادة المحاولة التلقائية (Retry Mechanism) عند حدوث أي خطأ مثل Stale Element Reference أو Timeout Exceptions. يتم المحاولة عدة مرات مع وقت انتظار بين كل محاولة لضمان استقرار العملية وعدم تعطيل سير العمل.
في حال تعذر الوصول إلى أحد الفلاتر أو القيم، يقوم البرنامج بتجاوز الفلتر والاستمرار في العمليات المتبقية.
التوازي لتسريع العملية:
تم استخدام مكتبة ThreadPoolExecutor لتنفيذ العديد من النوافذ بشكل متوازي، مما يسرع من عملية جمع البيانات بشكل كبير، ويقلل من الوقت المستغرق للوصول إلى جميع الخيارات المتاحة في الموقع.
حفظ البيانات بشكل فوري:
بعد جمع البيانات، يتم حفظها فورياً في ملفات CSV، مما يضمن عدم فقدان البيانات في حال حدوث أي طارئ أو توقف مفاجئ للنظام. يتم إنشاء ملف CSV جديد لكل عملية مستقلة، مع إضافة اسم عشوائي لكل ملف لتجنب أي تعارض في الأسماء.
تهيئة وإعداد متصفح الويب في الوضع "headless":
لضمان الكفاءة العالية في استخراج البيانات، تم تهيئة متصفح Google Chrome للعمل في وضع headless مما يقلل من استهلاك الموارد ويزيد من سرعة تنفيذ العمليات.
إدارة الاختيارات المتعددة لكل فلتر:
البرنامج يدعم اختيار خيارات متعددة لكل فلتر بشكل ديناميكي، حيث يقوم بالمرور على كافة الاختيارات المتاحة لكل فلتر: نوع السيارة، سنة الإنتاج، المصنع، الطراز، النماذج الفرعية، والسلاسل.
موقع التنفيذ:
- استخدمت مكتبة Selenium مع WebDriver للوصول إلى الموقع واستخراج المعلومات. تمت تهيئة البرنامج ليعمل بشكل متكامل مع Chrome
WebDriver، مع ضبط الإعدادات المناسبة لتسريع العملية وتخفيض استهلاك الموارد.
التحديات التي تم التعامل معها:
- التعامل مع استثناءات DOM الديناميكي:
- كان على الموقع التعامل مع تغييرات ديناميكية في DOM للموقع، وبالتالي كان من الضروري التعامل مع الأخطاء مثل StaleElementReferenceException التي تحدث عند تحديث العناصر أثناء التفاعل معها.
التأكد من استخراج جميع البيانات الممكنة:
- كانت بعض الفلاتر مثل Submodel وSeries تظهر وتختفي بناءً على الخيارات المحددة، وبالتالي تمت برمجة البرنامج للتعامل مع هذا التفاوت
في تواجد الفلاتر وضمان استخراج البيانات بأعلى دقة.
تسريع العملية عبر التوازي:
- بدلاً من تنفيذ العمليات بشكل متسلسل، قمت بزيادة كفاءة النظام عبر استخدام ThreadPoolExecutor لتشغيل عدة نوافذ متوازية تقوم
باستخراج البيانات في وقت واحد، مما قلل من زمن التشغيل الإجمالي.
التقنيات المستخدمة:
- Python: كلغة برمجية أساسية للمشروع.
- Selenium: للتفاعل مع الموقع الإلكتروني والتحكم في المتصفح.
- ThreadPoolExecutor: لتنفيذ العمليات بشكل متوازي.
- CSV: لتخزين البيانات المجمعة بطريقة منظمة وسهلة التصدير.
- Google Chrome WebDriver: لتمكين التصفح الآلي للموقع.
مخرجات المشروع:
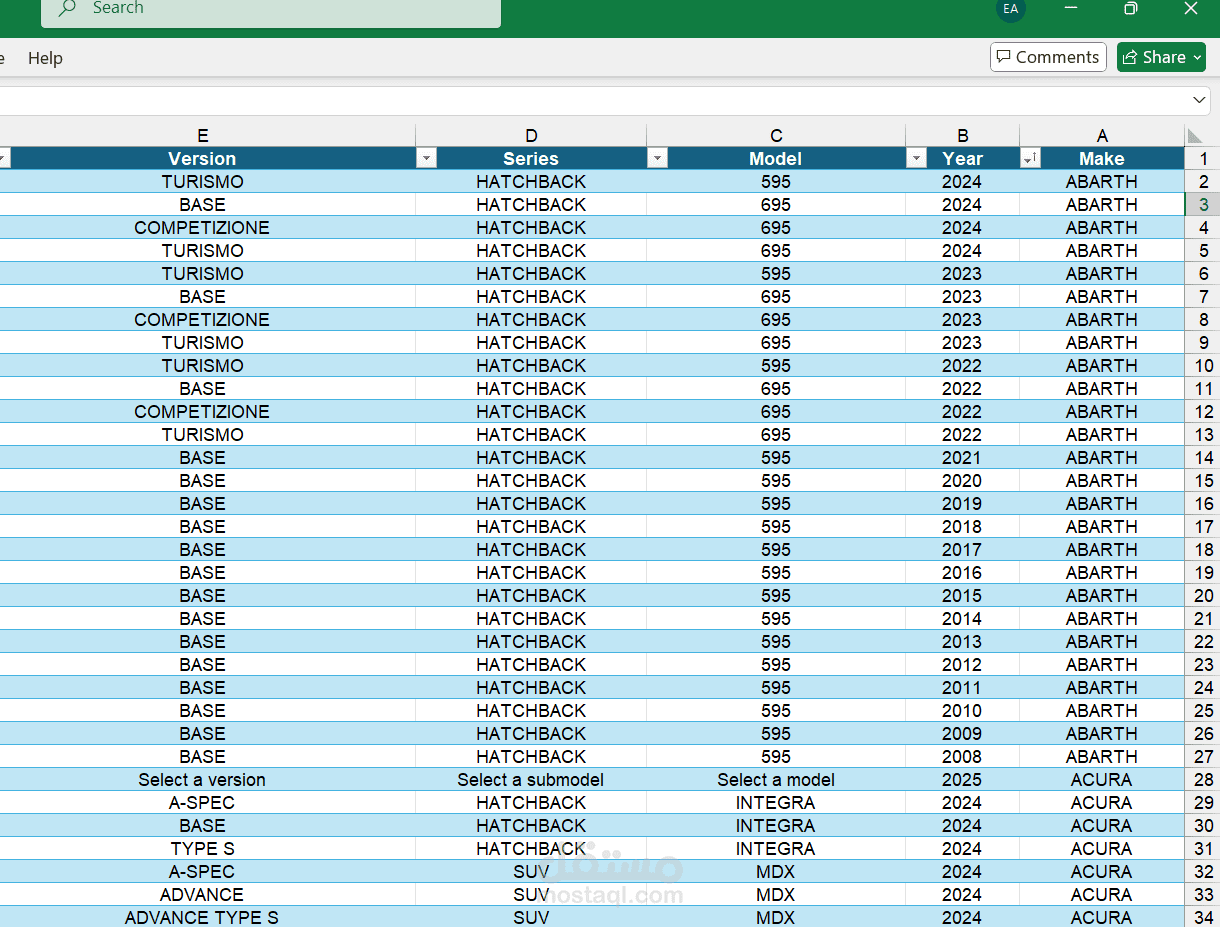
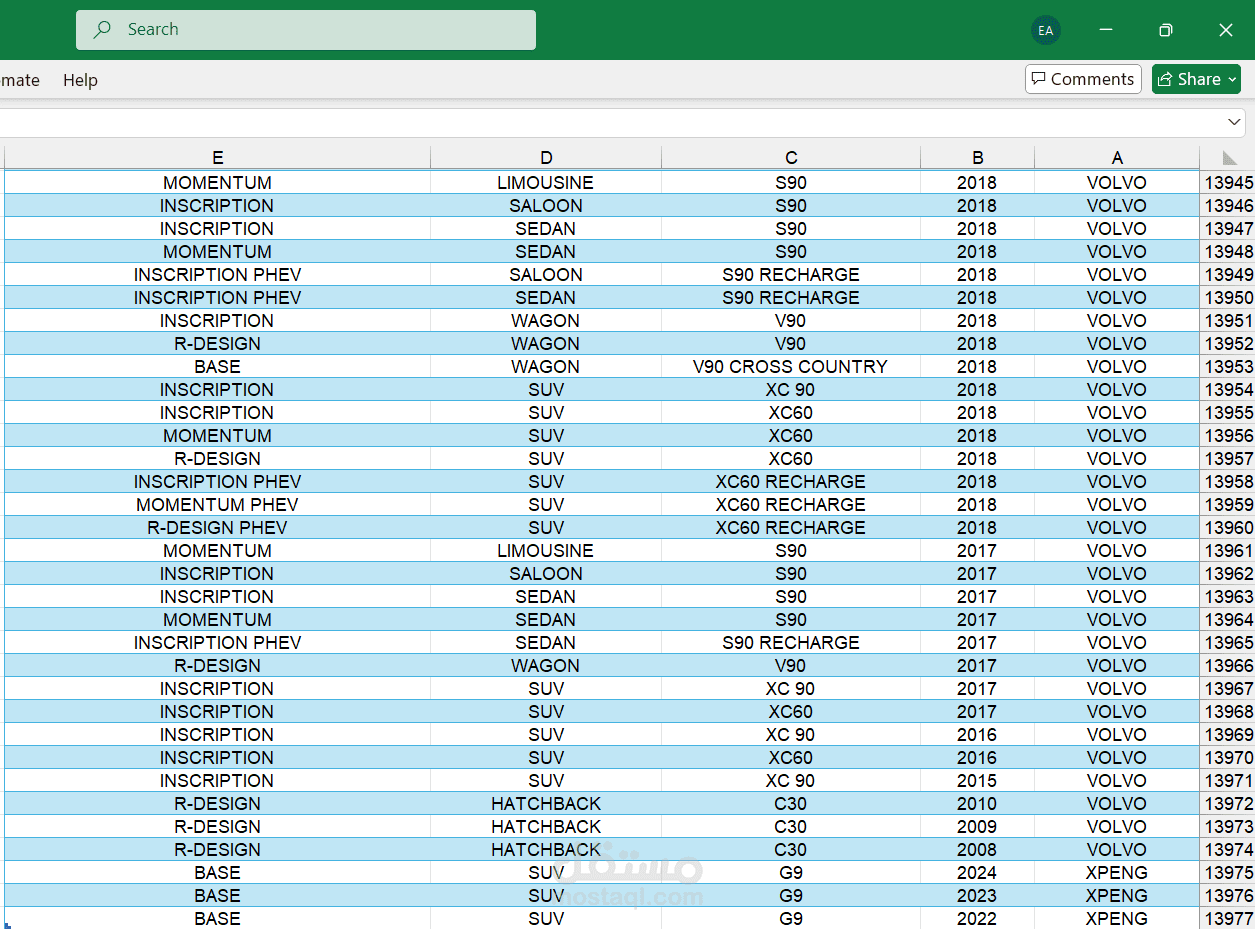
تم إنتاج العديد من ملفات CSV التي تحتوي على البيانات المستخرجة بشكل فوري ومنظم. تحتوي الملفات على بيانات مثل:
نوع السيارة
سنة التصنيع
المصنع
الطراز
النماذج الفرعية
السلاسل
خلاصة المشروع:
يعد هذا المشروع أحد الأمثلة المتقدمة على قدراتي في Web Scraping باستخدام Selenium وPython. من خلاله، تمكنت من بناء نظام متكامل يجمع البيانات من موقع معقد يحتوي على فلاتر ديناميكية ويعمل بكفاءة عالية، مما أضاف لي خبرة كبيرة في تحسين الأداء وحل المشاكل المتعلقة بالبيانات الديناميكية والمواقع الإلكترونية المعقدة.
بطاقة العمل
| اسم المستقل | Engy G. |
| عدد الإعجابات | 0 |
| عدد المشاهدات | 13 |
| تاريخ الإضافة | |
| تاريخ الإنجاز |