نظام تلخيص النصوص العربية باستخدام تقنيات التعلم العميق
تفاصيل العمل
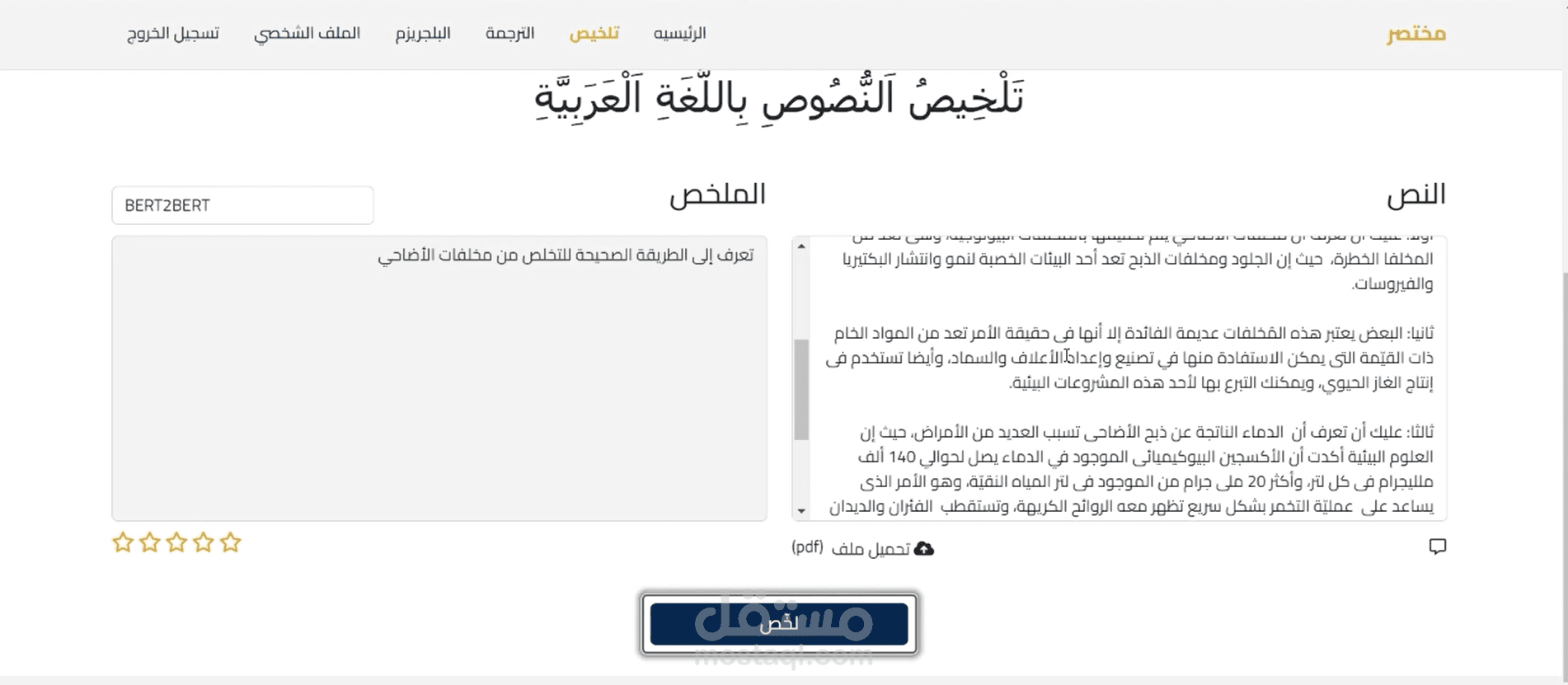
في هذا المشروع، تم تطوير نظام مبتكر لتلخيص النصوص العربية باستخدام تقنيات التعلم العميق، مع التركيز على إنشاء تلخيصات دقيقة ومختصرة للمحتوى النصي الأصلي. يعد هذا النظام مثاليًا للتطبيقات التي تتطلب معالجة سريعة وفعالة للمعلومات النصية، مما يسهم في توفير الوقت والجهد للمستخدمين.
مراحل تنفيذ المشروع:
جمع البيانات:
تم جمع مجموعة ضخمة من البيانات النصية باللغة العربية، تتألف من مقالات وأخبار وتقارير. تم تجهيز البيانات ومعالجتها للتأكد من جودتها وجاهزيتها لتدريب النموذج.
المعالجة المسبقة للنصوص:
تم تطبيق تقنيات المعالجة المسبقة للنصوص، مثل إزالة الضوضاء، وتحليل الجمل، وتجهيز النصوص للنماذج العميقة باستخدام أدوات مثل NLTK وspaCy المخصصة للغة العربية.
تطوير نماذج التعلم العميق:
استخدمت نماذج متقدمة مثل seq2seq وTransformer، بالإضافة إلى نماذج مدربة مسبقًا مثل AraGPT2 وAraT5. هذه النماذج تم تدريبها على النصوص العربية لتوليد تلخيصات دقيقة وموجزة للنصوص.
تحسين النموذج وتقييم الأداء:
تم تحسين أداء النماذج باستخدام تقنيات مثل Fine-tuning وHyperparameter Tuning لضبط النموذج وفقًا لاحتياجات التلخيص. تم تقييم النموذج باستخدام مقاييس مثل ROUGE وBLEU لتحديد مدى دقة التلخيص.
التحديات وحلولها:
نظرًا للطبيعة اللغوية المعقدة للغة العربية، تم التعامل مع تحديات مثل التشابه اللغوي وتعدد المعاني من خلال تحسين البيانات المدخلة وضبط النماذج بشكل دقيق.
الأدوات والتقنيات المستخدمة:
البرمجة: Python
التعلم العميق: seq2seq, Transformer, AraGPT2, AraT5
معالجة اللغة الطبيعية (NLP): NLTK, spaCy, Hugging Face
مجموعات البيانات: تم استخدام مجموعات نصية ضخمة باللغة العربية من مصادر متنوعة
النتائج:
النظام حقق دقة عالية في تلخيص النصوص العربية، حيث يوفر تلخيصات مختصرة وفعالة بدون التضحية بجودة المحتوى أو دقته.
يسهم المشروع في توفير أدوات جديدة وفعالة لمعالجة النصوص العربية في المجالات الأكاديمية، الصحفية، والتجارية.
الملفات المرفقة:
يمكن الاطلاع على الأكواد المصدرية الخاصة بالنماذج المستخدمة من خلال Jupyter Notebooks، مع توضيحات لكل مرحلة من مراحل التطوير.
تم إرفاق أمثلة تلخيصات متعددة لاختبار النظام والتحقق من دقته.