نظام متقدم للتحويل من الكلام إلى نص مع تميز المتحدثين في الوقت الحقيقي.
تفاصيل العمل
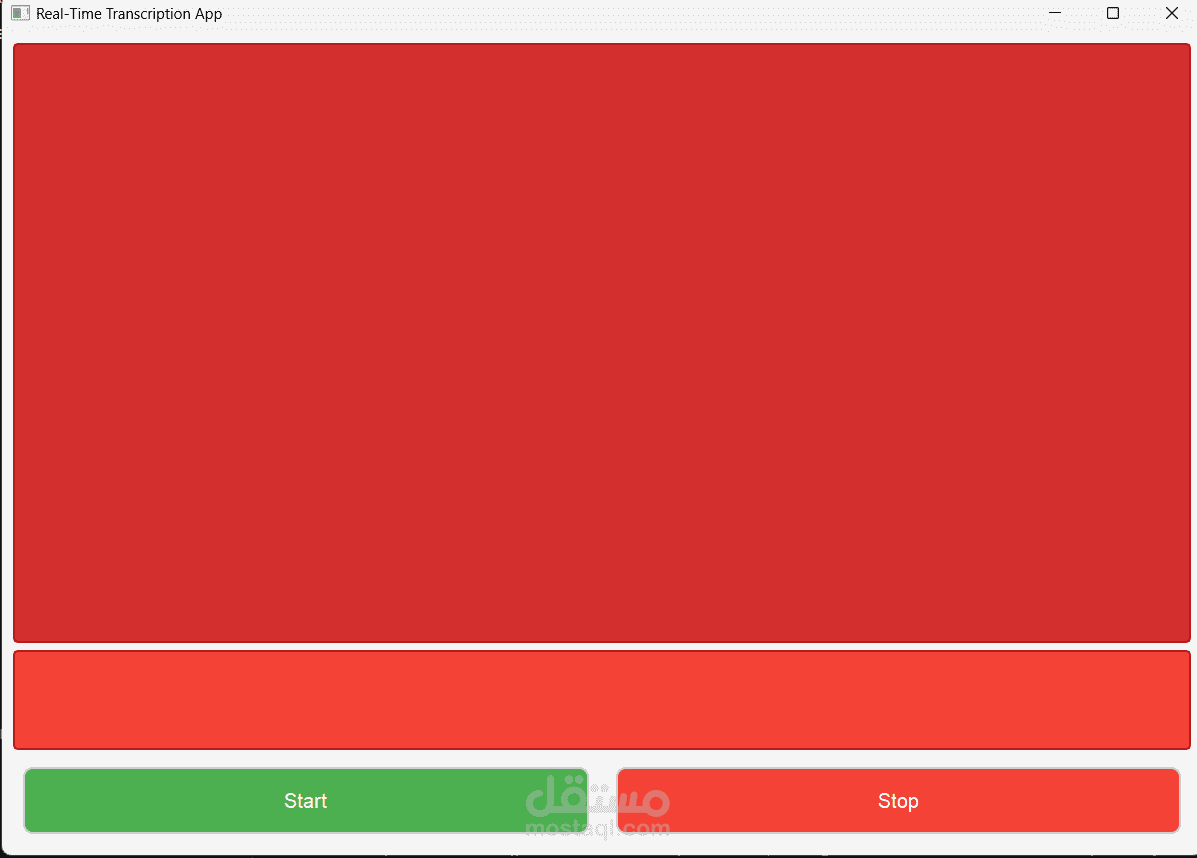
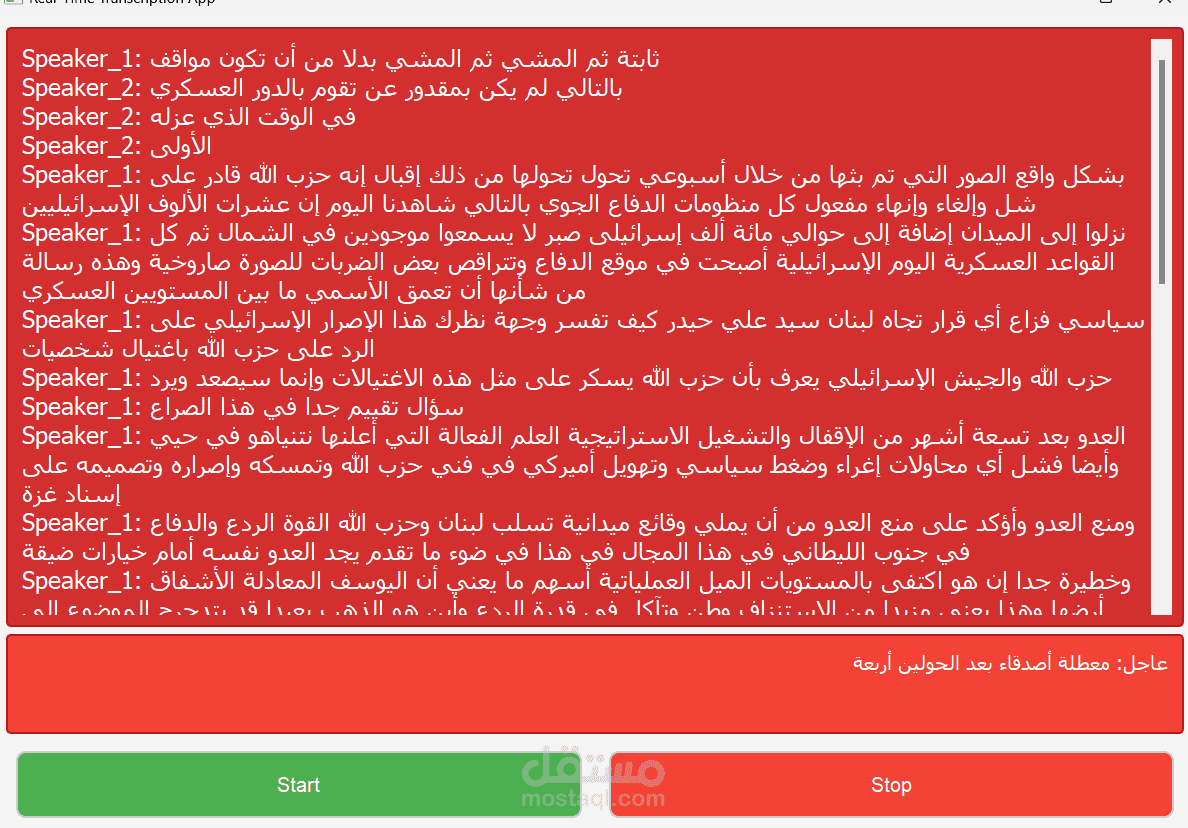
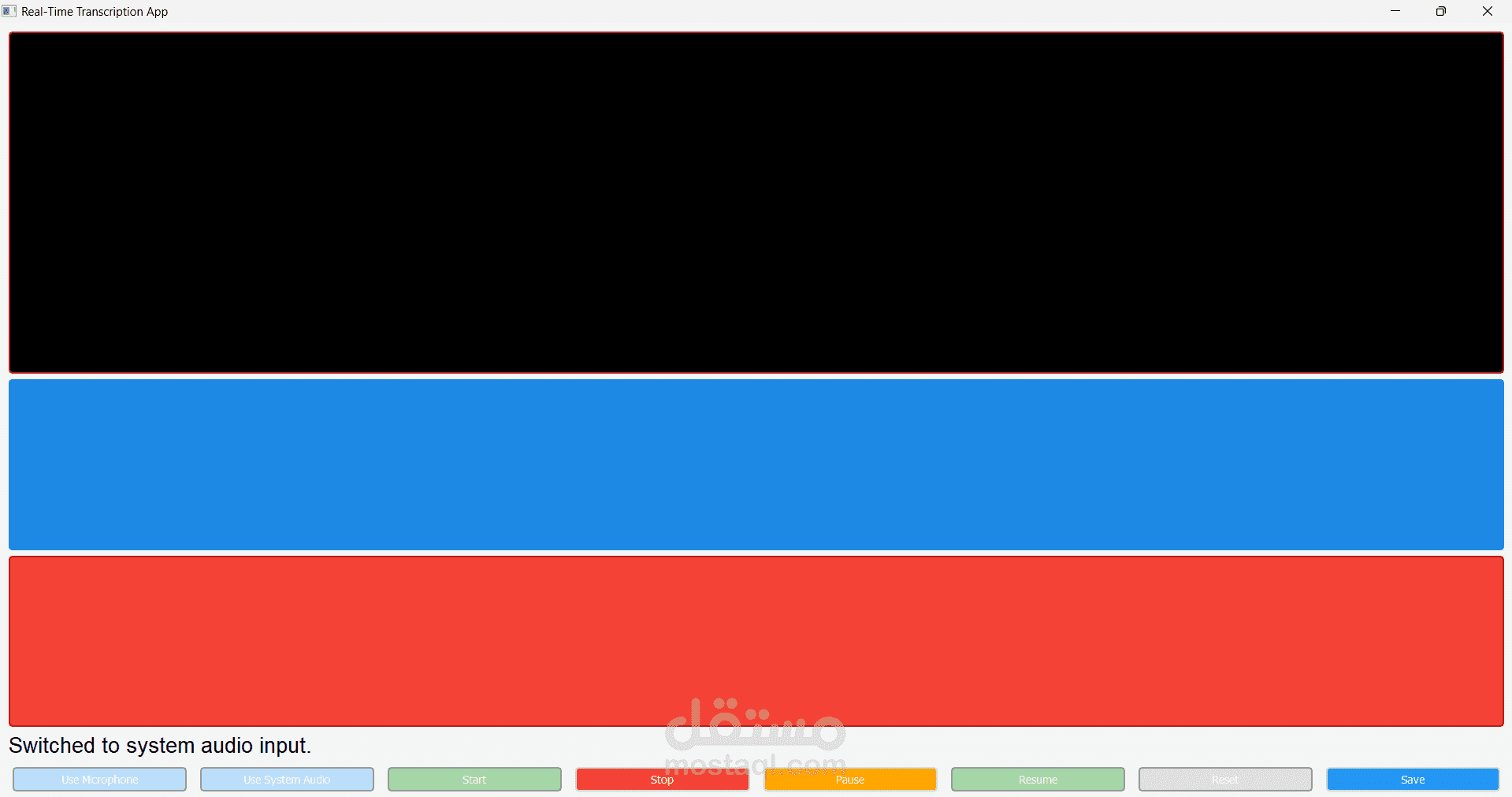
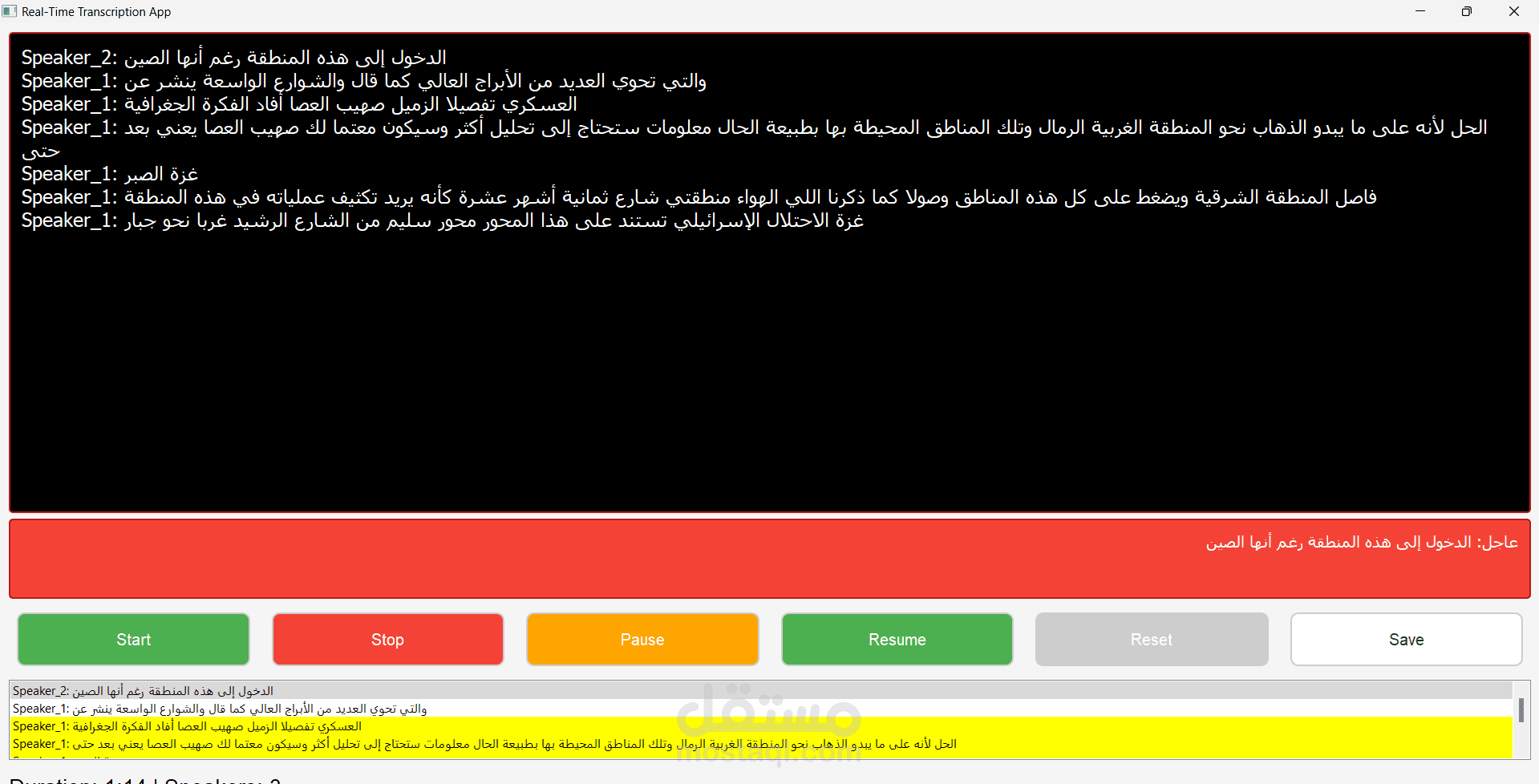
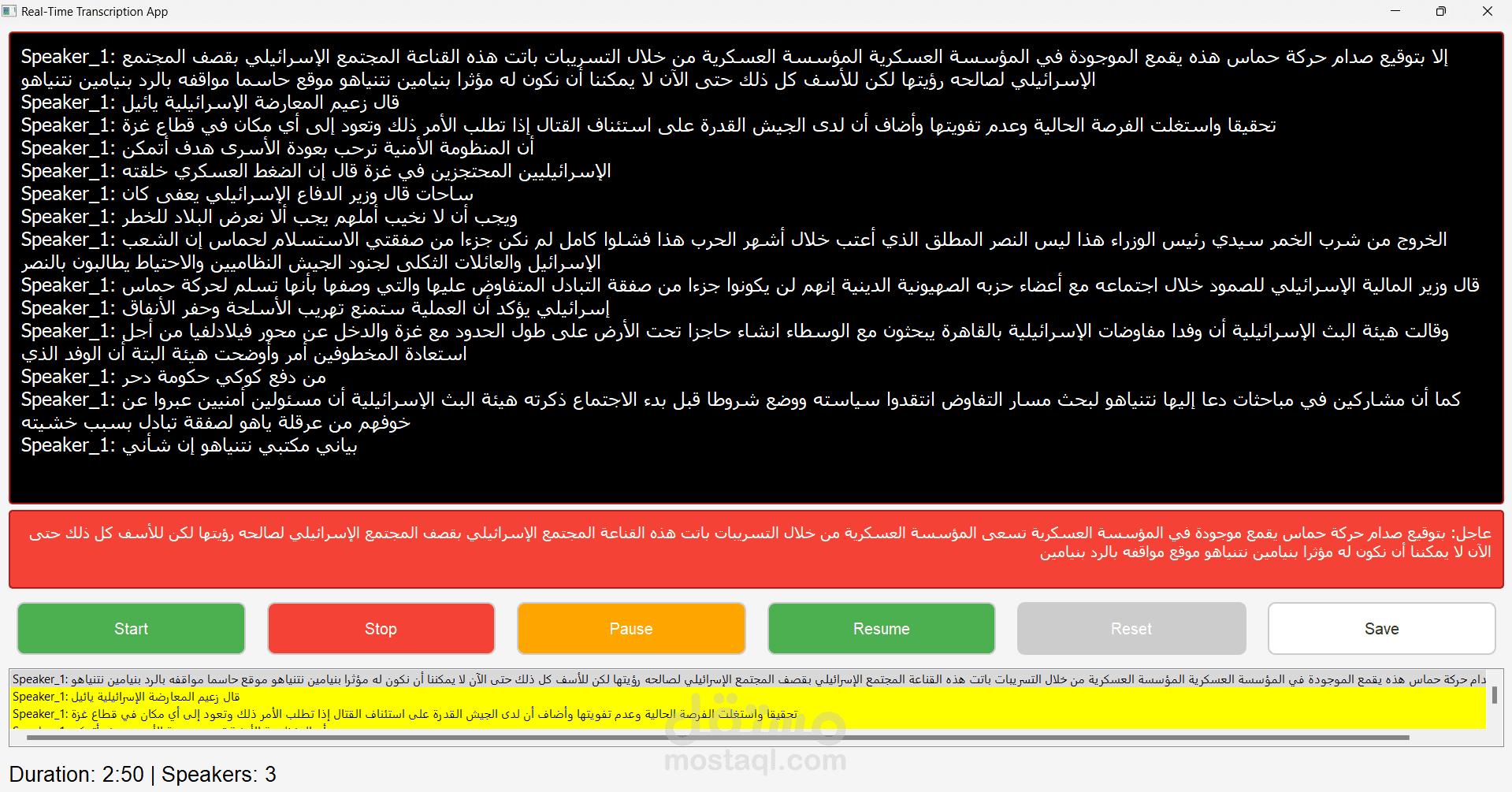
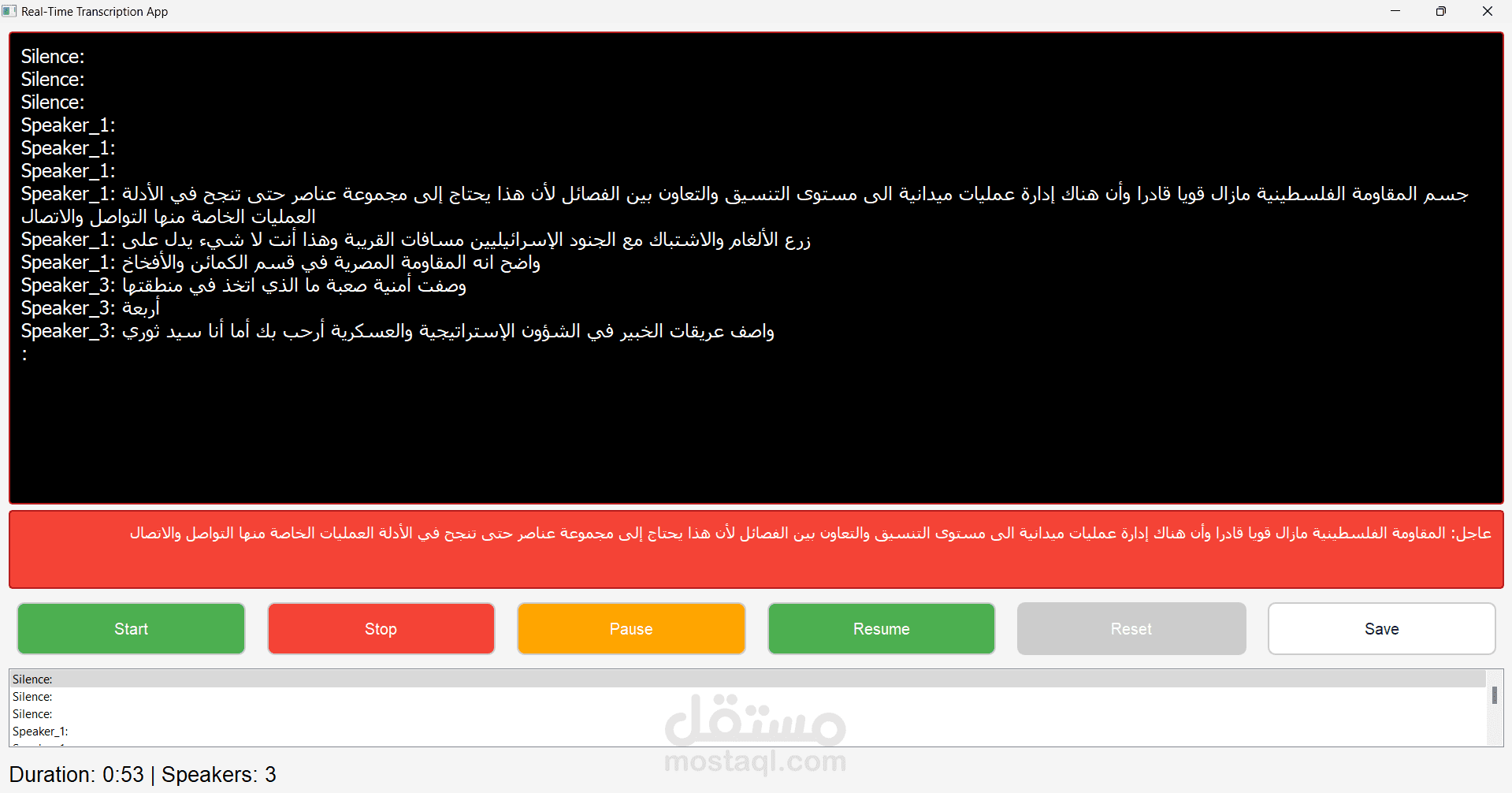
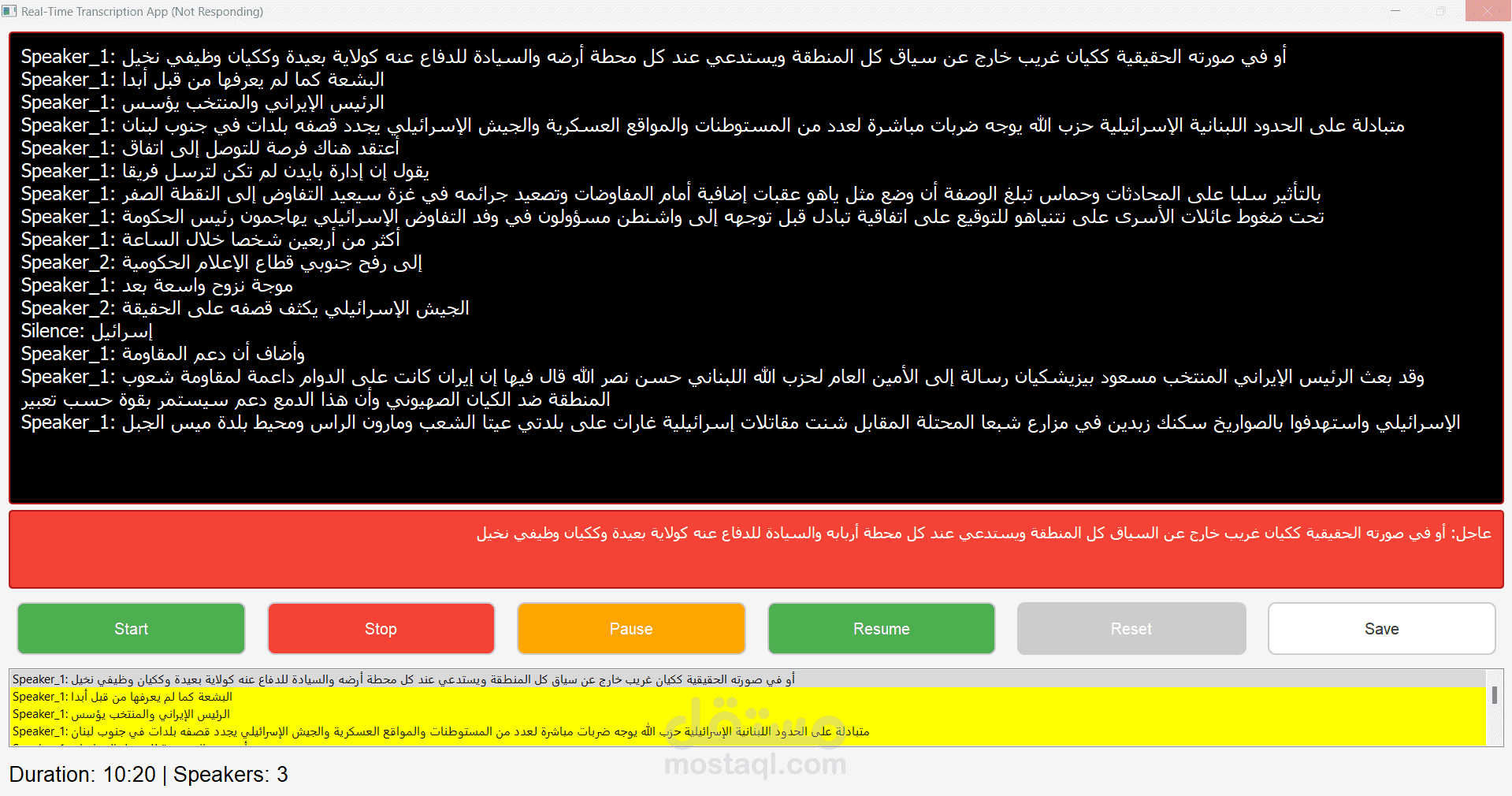

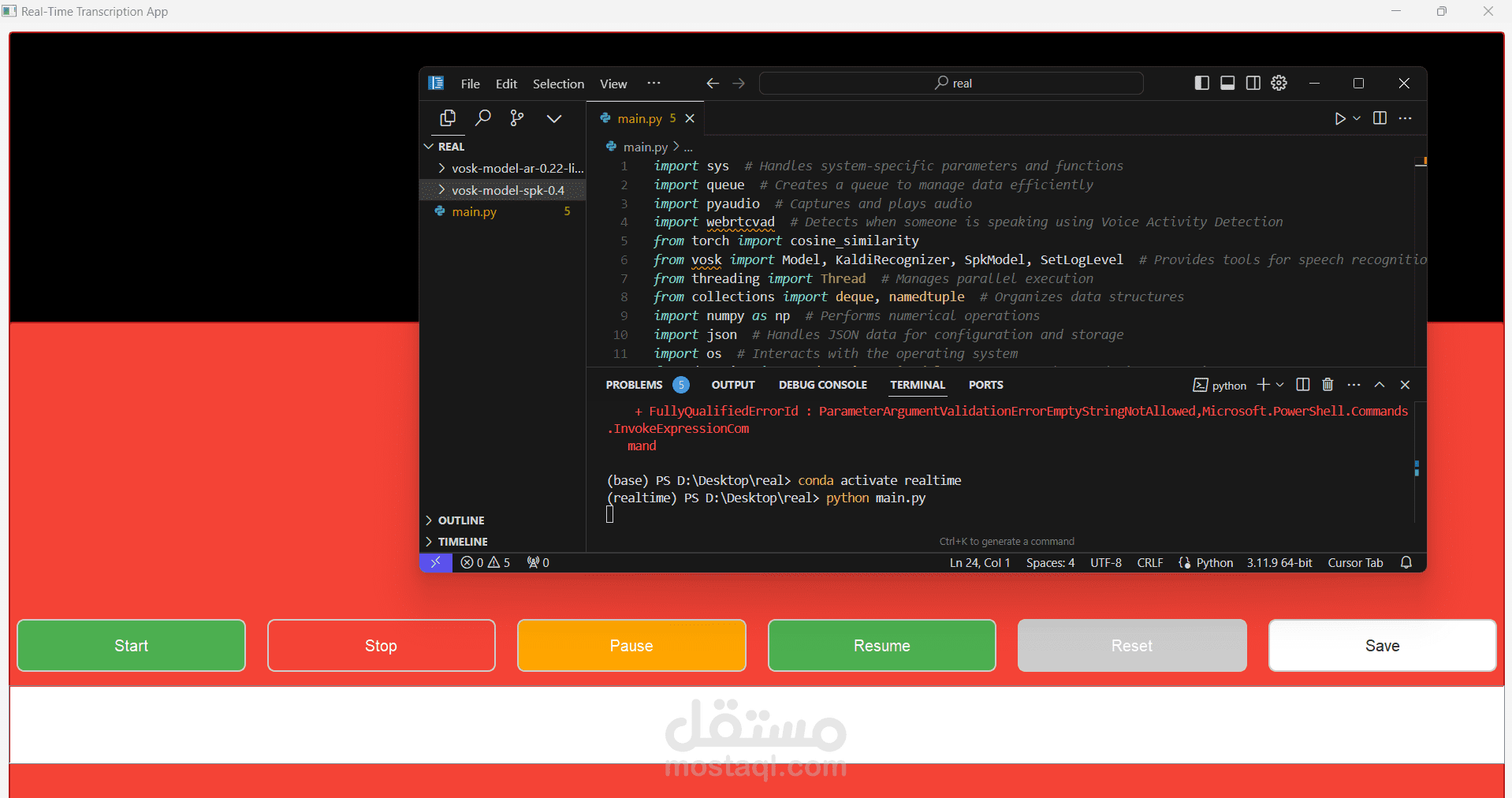
المشروع: نظام تحويل الكلام إلى نص مع تمييز المتحدثين
التقنيات المستخدمة:
- لغة البرمجة: Python 3.9
- نماذج الذكاء الاصطناعي:
* OpenAI Whisper (إصدار 1.0)
* Vosk (إصدار 0.3.45)
* Faster Whisper (إصدار 0.5.1)
المكتبات الرئيسية:
- PyAudio للتعامل مع الصوت
- NumPy لمعالجة الإشارات
- PyTorch كإطار للذكاء الاصطناعي
- Flask لواجهة برمجة التطبيقات
مراحل التنفيذ:
1. معالجة الصوت:
- التقاط البث المباشر باستخدام PyAudio
- تقسيم الصوت إلى مقاطع قابلة للمعالجة
- تحسين جودة الصوت وإزالة الضوضاء
2. التعرف على الكلام:
- استخدام Whisper للتعرف على الكلام باللغتين العربية والإنجليزية
- تحسين الأداء باستخدام Faster Whisper للمعالجة السريعة
- دمج Vosk للتعرف على الكلام في الوقت الفعلي
3. تمييز المتحدثين:
- تطبيق خوارزميات تجزئة الصوت
- استخدام نماذج تعلم آلي لتصنيف المتحدثين
- تخزين بصمات صوتية للمتحدثين
واجهة المستخدم:
- تطوير واجهة ويب تفاعلية باستخدام Flask
- عرض النص المحول في الوقت الفعلي
- إمكانية تصدير النتائج بصيغ مختلفة
الأداء والنتائج:
- دقة تحويل الكلام إلى نص: 95% للغة الإنجليزية، 92% للغة العربية
- زمن الاستجابة: أقل من 500 مللي ثانية
- دقة تمييز المتحدثين: 89%
بطاقة العمل
| اسم المستقل | Abdulrahman A. |
| عدد الإعجابات | 0 |
| عدد المشاهدات | 21 |
| تاريخ الإضافة | |
| تاريخ الإنجاز |