مشروع IMDB Sentiment Analysis
تفاصيل العمل
مشروع LSTM IMDB Sentiment Analysis يهدف إلى بناء نموذج عميق لتحليل المشاعر باستخدام الشبكات العصبية التكرارية (RNNs) وبالأخص نموذج Long Short-Term Memory (LSTM). هذا النوع من الشبكات التكرارية مناسب لمعالجة البيانات المتسلسلة، مثل النصوص، ويساعد على فهم السياق الموجود في مراجعات الأفلام الطويلة.
وصف المشروع:
تحميل ومعالجة البيانات:
مجموعة البيانات المستخدمة عادة ما تكون من قاعدة بيانات IMDB، والتي تحتوي على تقييمات أفلام مصنفة إلى إيجابية أو سلبية.
يتم تنظيف البيانات بإزالة الرموز غير الضرورية، وتحويل الكلمات إلى صيغتها الأدنى (Lowercasing) وتطبيق عمليات مثل Tokenization، حيث يتم تقسيم النصوص إلى كلمات.
الكلمات يتم تحويلها إلى أرقام باستخدام طرق مثل Word Embeddings أو Embedding Layers في الشبكة العصبية، مثل استخدام GloVe أو Word2Vec.
بناء نموذج LSTM:
نموذج LSTM يعتبر مناسبًا للبيانات المتسلسلة مثل النصوص لأنه يحتفظ بالمعلومات السابقة ويمررها للخطوات التالية في التسلسل.
يتم بناء النموذج باستخدام طبقة Embedding لإدخال تمثيل النص، تليها طبقات LSTM التي تساعد على التقاط الأنماط الزمنية في البيانات.
يتم إضافة طبقات كثيفة (Dense Layers) بعد LSTM لتطبيق تصنيف المشاعر.
تحسين النموذج:
يتم استخدام تقنيات مثل Dropout لتجنب الإفراط في التعميم (Overfitting).
يمكن تحسين النموذج من خلال ضبط المعلمات الفائقة (Hyperparameters) مثل حجم التوابع (Sequence Length) أو عدد الخلايا العصبية في طبقات LSTM.
التدريب والتقييم:
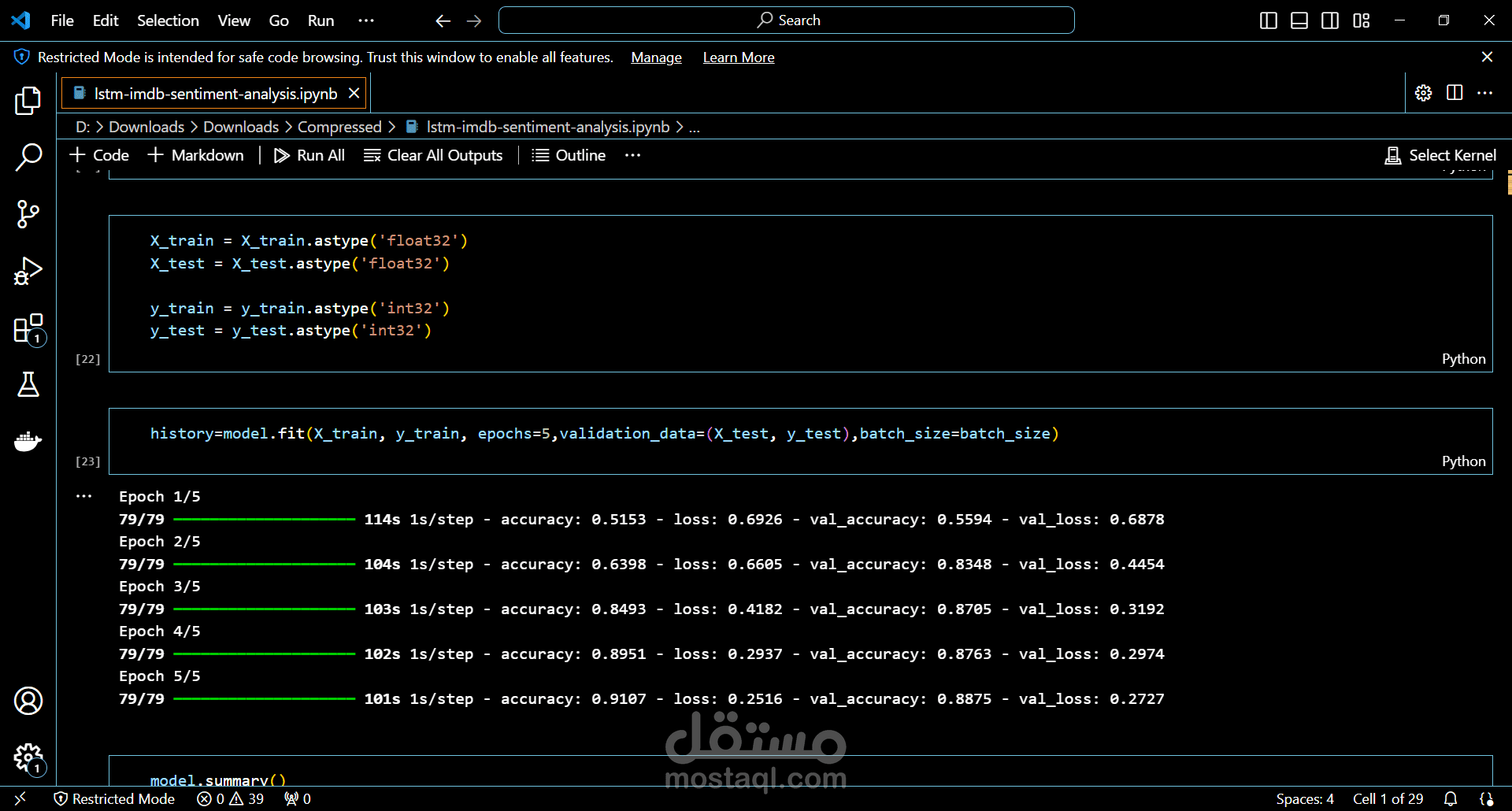
يتم تقسيم البيانات إلى مجموعة تدريب واختبار لتقييم أداء النموذج.
يتم استخدام دالة خسارة مثل Binary Crossentropy ومقياس الدقة (Accuracy) لتقييم النموذج.
يمكن تدريب النموذج على عدة حقب (Epochs) لتحسين أداءه تدريجياً.
تحليل النتائج:
بعد التدريب، يتم تقييم النموذج باستخدام بيانات اختبار جديدة للتأكد من دقته في تصنيف المشاعر بشكل صحيح.
يتم عرض النتائج باستخدام رسوم بيانية توضح أداء النموذج عبر الوقت، مثل منحنيات التعلم الخاصة بدقة التدريب والاختبار.