Machine learning classification and data cleaning
تفاصيل العمل
my project involves several steps of data processing and analysis, starting with loading a dataset , handling duplicates, missing values, and applying transformations such as encoding and normalization. Here's an overview of the task:
1. **Data Cleaning and Preparation**:
- **Duplicate Handling**: Checks for duplicate rows in the dataset.
- **Missing Values**: Fills missing values and exports the filled data.
- **Encoding**: Converts categorical values (like `bechdelRating`) into dummy/indicator variables for easier model integration.
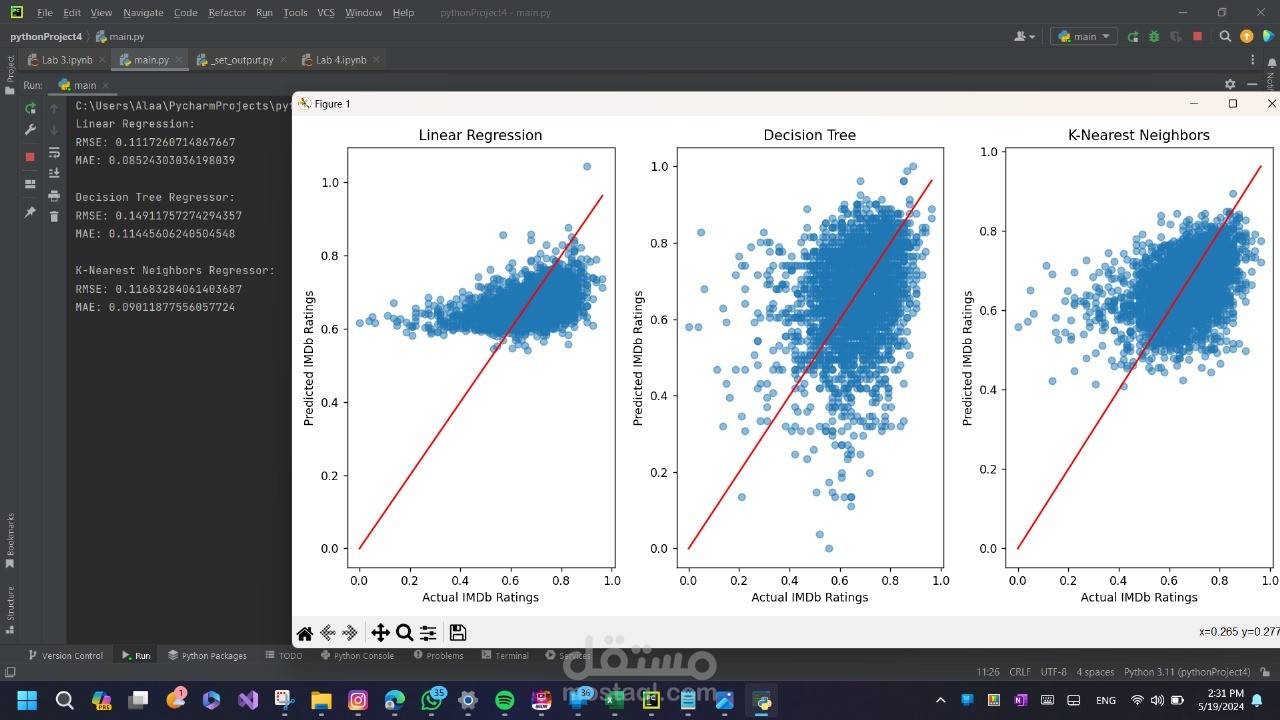
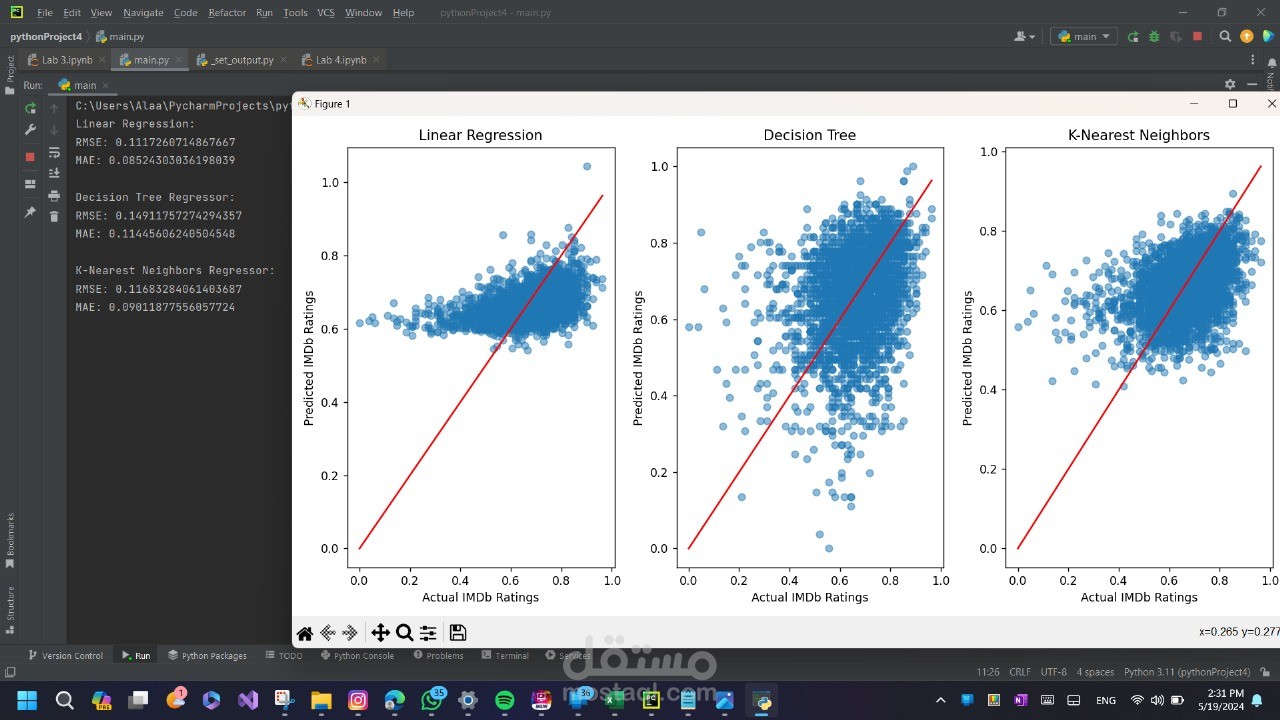
- **Normalization**: Applies MinMaxScaler to numerical columns like `runtimeMinutes` and `imdbAverageRating` and visualizes the before/after normalization with histograms.
2. **Classification**:
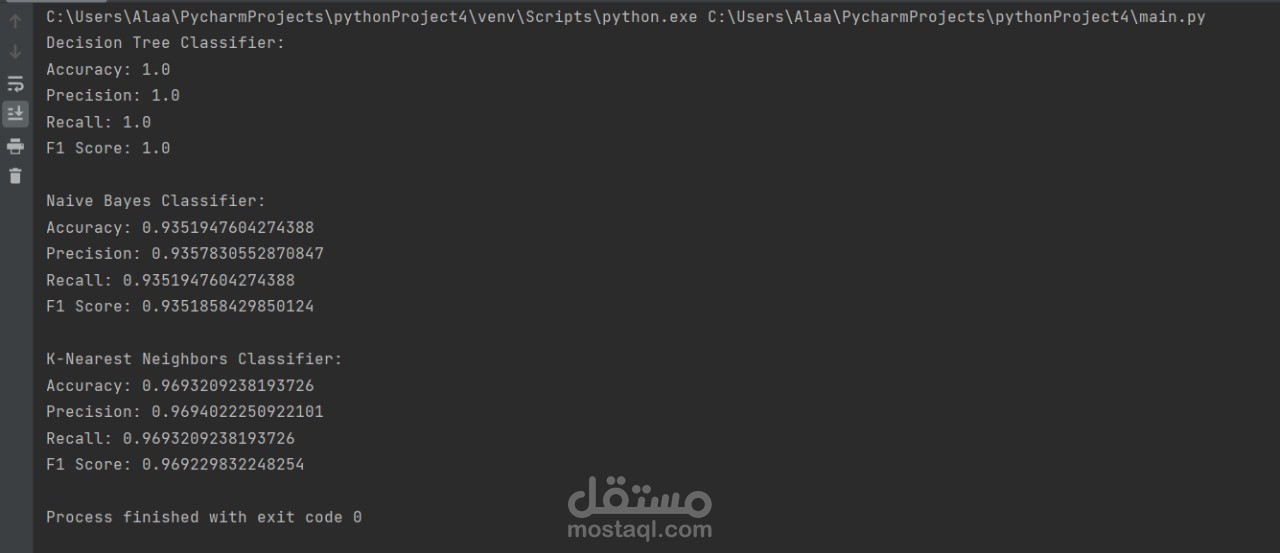
- **Rating Classification**: A custom function classifies IMDb ratings into categories ('Bad', 'Good', 'Excellent') based on set thresholds.
- **Decision Tree Classifier**: Splits the data into training and test sets, trains a decision tree model, and evaluates it using accuracy, precision, recall, and F1 score. The results are saved to a file.
3. **Regression**:
- **Linear Regression**: Trains a linear regression model to predict IMDb ratings based on features like `runtimeMinutes` and `year`. The performance is evaluated using RMSE (Root Mean Squared Error) and MAE (Mean Absolute Error), and the predictions are visualized with a scatter plot of actual vs. predicted values.
Each step of the process ensures the data is cleaned, transformed, and modeled to provide insights into both classification and regression tasks.