"نموذج تصنيف السخرية في العناوين الإخبارية باستخدام معالجة النصوص الطبيعية (NLP)"
تفاصيل العمل
وصف المشروع
"في هذا المشروع، تم تطوير نموذج للتعلم الآلي يعتمد على تقنيات معالجة النصوص الطبيعية (NLP) لتصنيف العناوين الإخبارية إلى ساخرة أو غير ساخرة. تم استخدام مجموعة بيانات تحتوي على آلاف العناوين من مصادر إخبارية متنوعة مثل 'The Onion' و'HuffPost' لبناء النموذج. يشمل المشروع معالجة البيانات، واستخراج الميزات اللغوية، وتطبيق خوارزميات التعلم العميق لتحسين دقة التصنيف. يهدف المشروع إلى تقديم أداة فعالة لتحليل وتحديد العناوين الإخبارية الساخرة بدقة عالية."
التقنيات المستخدمه:
معالجة البيانات الأولية:
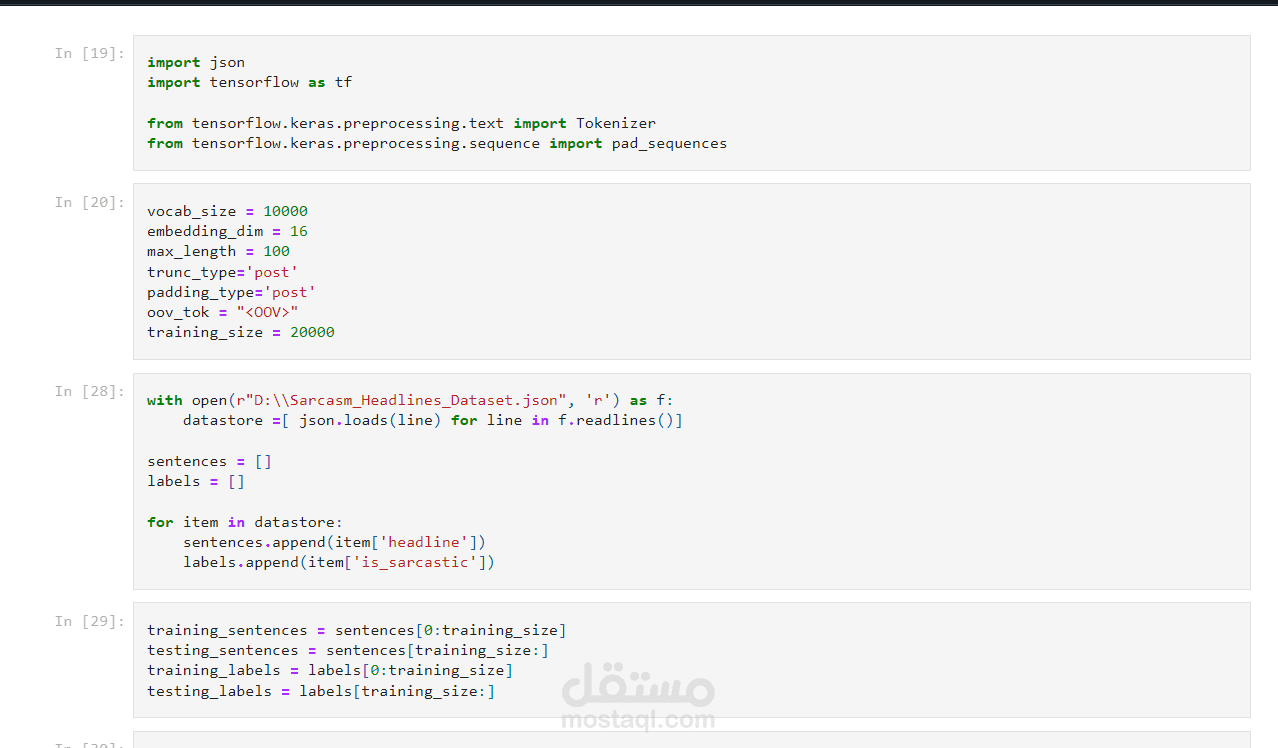
استخدام مكتبات مثل pandas وNumPy لتنظيف البيانات ومعالجتها (إزالة العلامات الزائدة، تصحيح الأخطاء، تحويل النصوص إلى صيغ مناسبة للتحليل).
تحويل النصوص إلى متجهات:
استخدام طرق مثل TF-IDF (Term Frequency-Inverse Document Frequency) أو Word Embeddings مثل Word2Vec أو GloVe لتحويل الكلمات إلى متجهات رقمية يمكن للموديل التعامل معها.
يمكن أيضًا استخدام تقنية التحويلات (Transformers) مثل BERT لتحليل السياق في النصوص بشكل أكثر دقة.
التصنيف باستخدام النماذج التقليدية والحديثة:
نماذج تقليدية: مثل Logistic Regression، Naive Bayes، وSupport Vector Machine (SVM) لتصنيف النصوص.
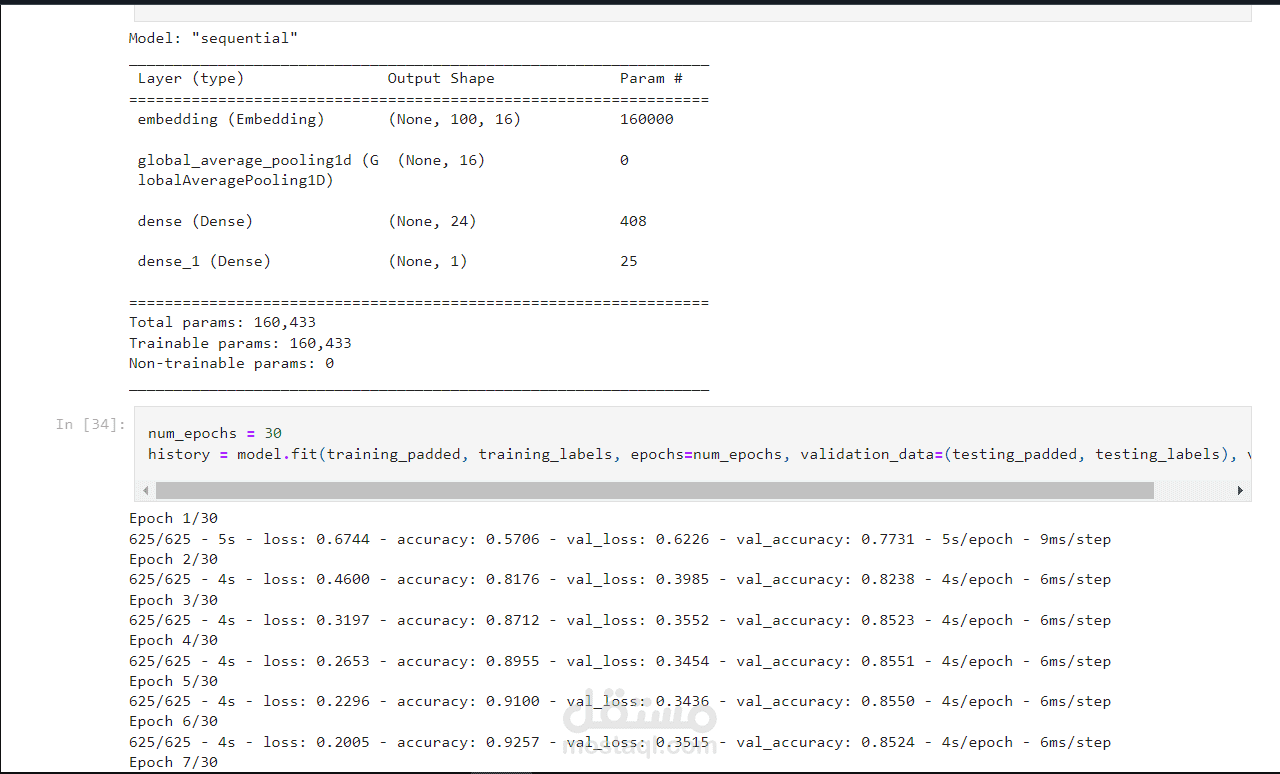
التعلم العميق: استخدام الشبكات العصبية مثل LSTM (Long Short-Term Memory) أو GRU (Gated Recurrent Unit) لتحليل التسلسل في النصوص.
يمكن أيضًا استخدام النماذج القائمة على التحويلات (Transformers) مثل BERT أو RoBERTa للحصول على دقة أعلى في التصنيف.
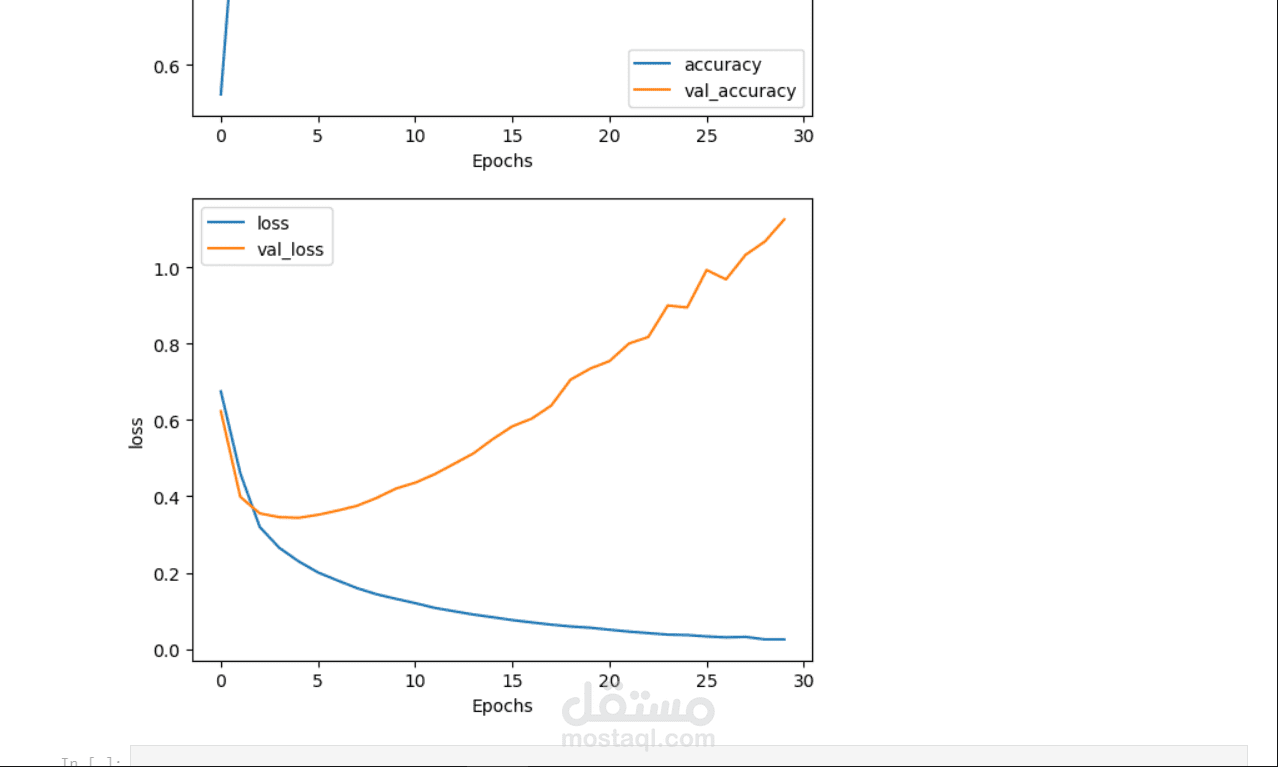
تحسين النموذج وتقييم الأداء:
استخدام طرق مثل Cross-Validation لتقييم أداء النموذج.
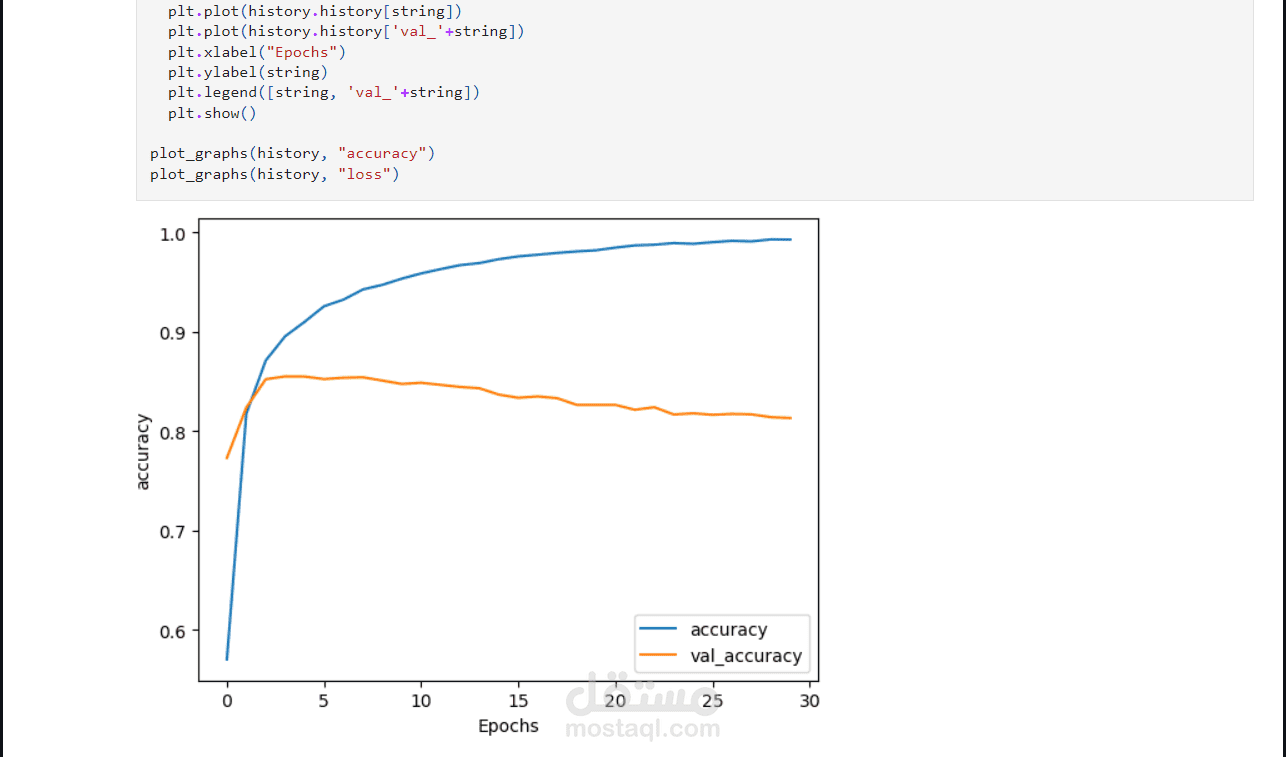
تطبيق مصفوفة الالتباس (Confusion Matrix)، ومقياس F1، ودقة النموذج (Accuracy) لقياس أداء ا
استخدمنا لغة برمجة البايثون استخدمنا عددة مكتبات مثل NLTK,Pandas , Numpy , Matplotlip.
استخدم تقنيات مثل الشبكات العصبية (CNN) للتعرف علي صورة النبات
استخدم ايضا Tensorflow و Kears
استخدم نموذج ثلاثي الابعاد لتوضيح الكلمات السخريه والغير اخلاقيه
استخدم برامج مثل VScode and Jupyter
بطاقة العمل
| اسم المستقل | Mohamed S. |
| عدد الإعجابات | 0 |
| عدد المشاهدات | 8 |
| تاريخ الإضافة |