Noon WebScraping
تفاصيل العمل

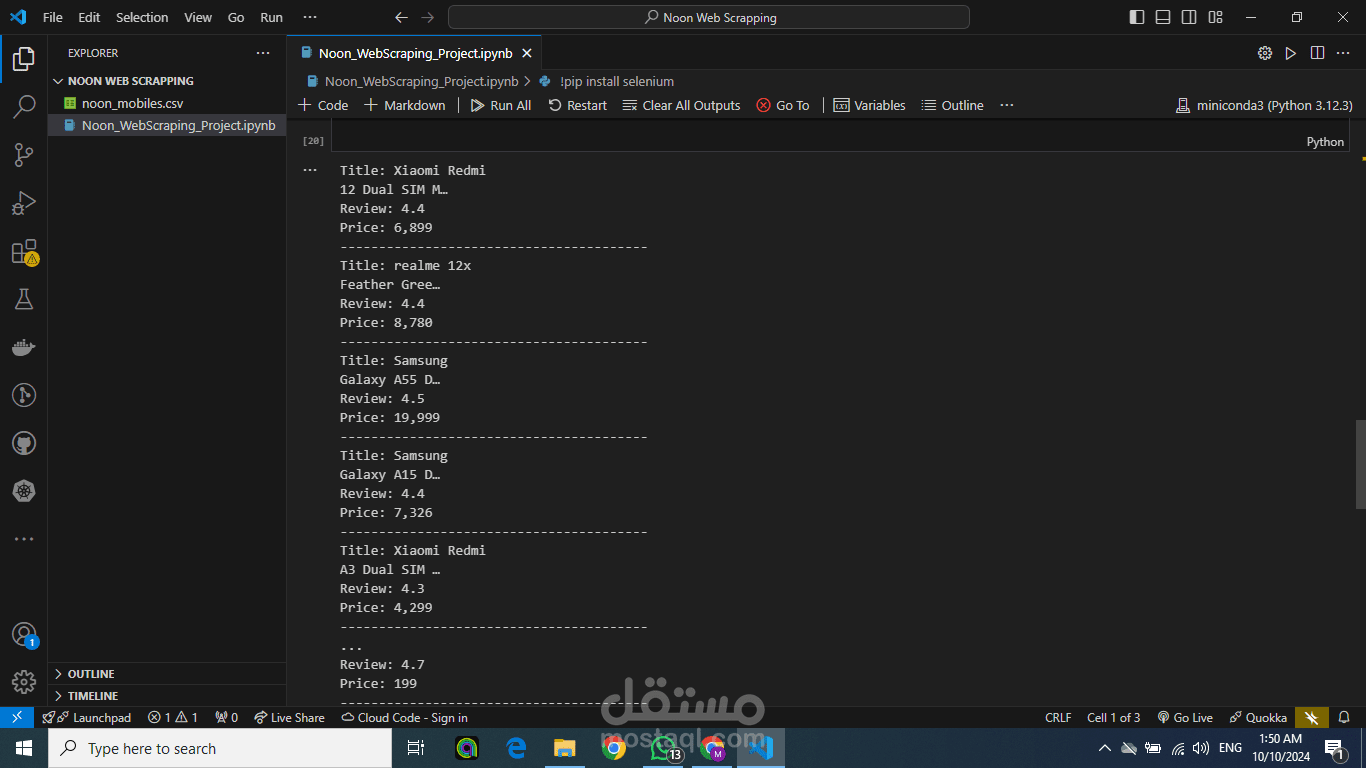
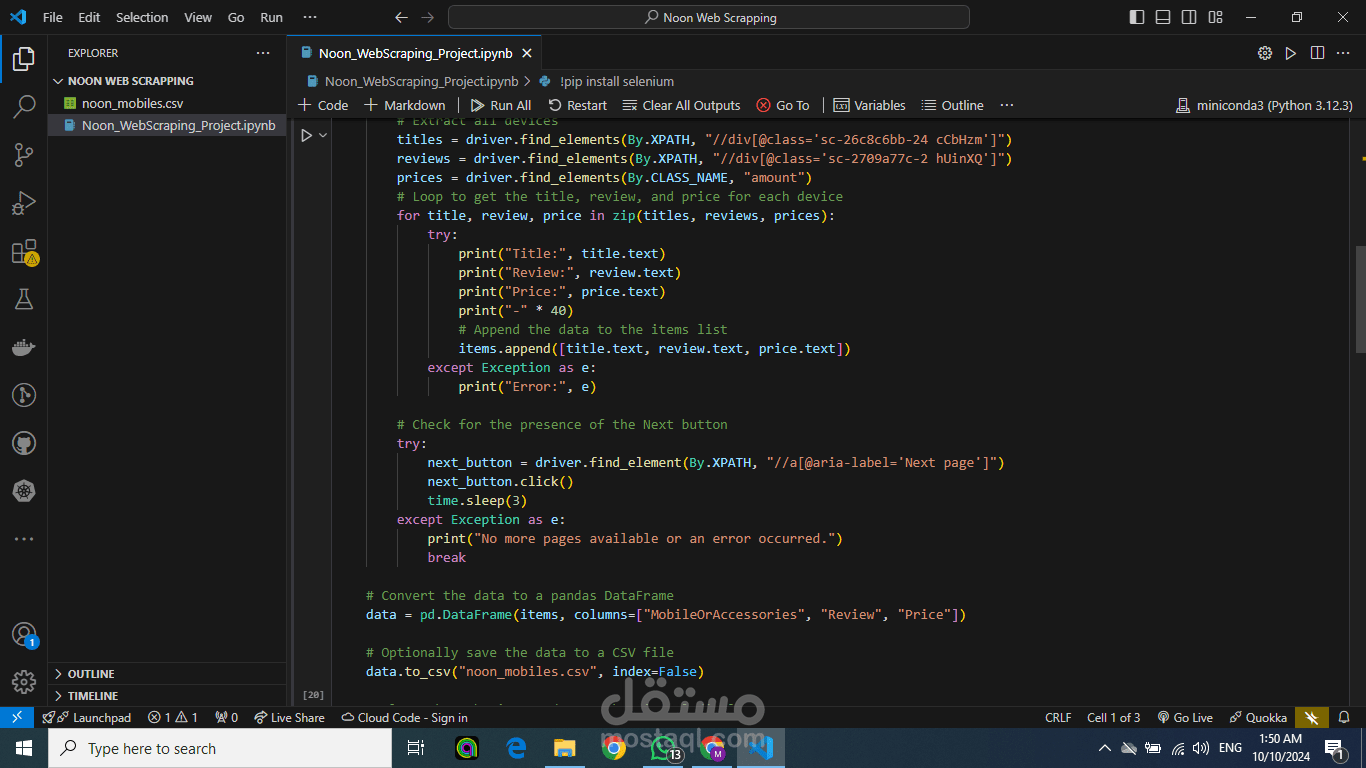
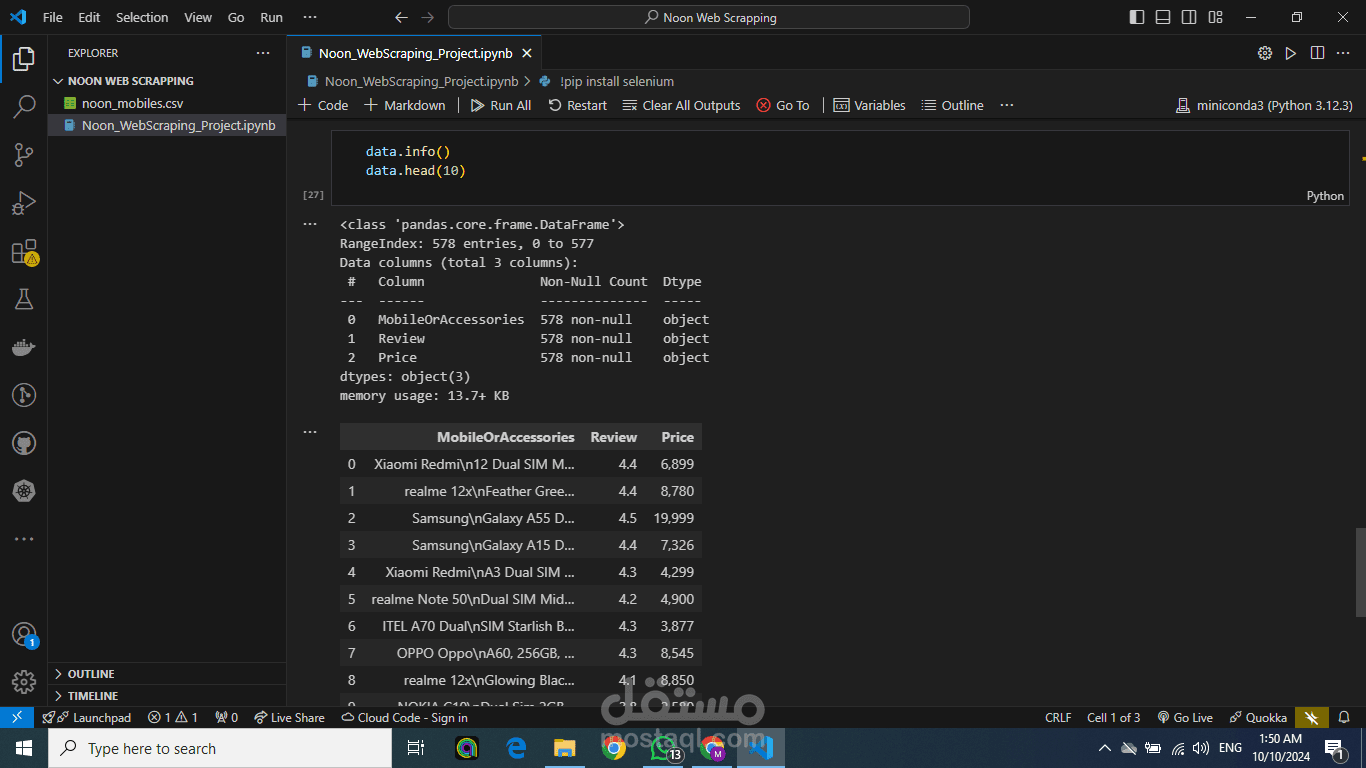
يهدف هذا التقرير إلى شرح خطوات استخراج البيانات من موقع نون وتحليلها باستخدام لغة البرمجة Python ومكتباتها المتخصصة. البيانات التي تم استخراجها تشمل معلومات عن الهواتف المحمولة وإكسسواراتها مثل الأسماء، الأسعار، والمراجعات من المستخدمين.
1. استيراد المكتبات وتجهيز بيئة العمل:
في البداية، يتم تحميل المكتبات الأساسية الخاصة بلغة Python، التي تلعب دورًا مهمًا في تنفيذ عملية استخراج وتحليل البيانات:
Requests: مكتبة تُستخدم في بايثون لإرسال طلبات HTTP لجلب صفحات الويب المطلوبة من موقع "نون".
BeautifulSoup: مكتبة أخرى متخصصة في Python تُستخدم لتحليل محتوى صفحات الويب واستخراج البيانات المطلوبة من هياكل HTML.
Pandas: مكتبة بايثون قوية تُستخدم لتنظيم البيانات على شكل جداول (DataFrames) وتسهيل عملية تحليلها.
2. استخراج البيانات (Web Scraping):
باستخدام لغة Python ومكتبة BeautifulSoup، تتم عملية استخراج البيانات من موقع "نون". في هذا الجزء، يقوم الكود البرمجي بتنفيذ عدة مهام:
إرسال طلبات HTTP لجلب صفحات المنتجات باستخدام مكتبة Requests. يتم استخدام هذه المكتبة لجلب الصفحة التي تحتوي على معلومات الهواتف المحمولة.
تحديد العناصر المطلوبة في الصفحة (مثل أسماء المنتجات، الأسعار، والمراجعات) من خلال تحليل بنية HTML باستخدام BeautifulSoup. يتم البحث عن علامات محددة مثل <div> و<span> لاستخراج المعلومات ذات الصلة.
استخراج البيانات: بعد تحديد العناصر المطلوبة في الصفحة، يتم استخراج البيانات المهمة مثل الأسماء، الأسعار، والتقييمات باستخدام تقنيات تحليل DOM في مكتبة BeautifulSoup.
تخزين البيانات في قائمة منظمة: بعد استخراج البيانات، يتم تخزينها في قائمة منظمة (List) لسهولة معالجتها لاحقًا.
حفظ البيانات في ملف CSV: بعد تنظيم البيانات وتحويلها إلى إطار بيانات (DataFrame) باستخدام مكتبة Pandas، يتم حفظها في ملف CSV. يُستخدم هذا الملف لتخزين البيانات بشكل منظم وقابل لإعادة الاستخدام أو لمزيد من التحليل في وقت لاحق.