TriFind
تفاصيل العمل
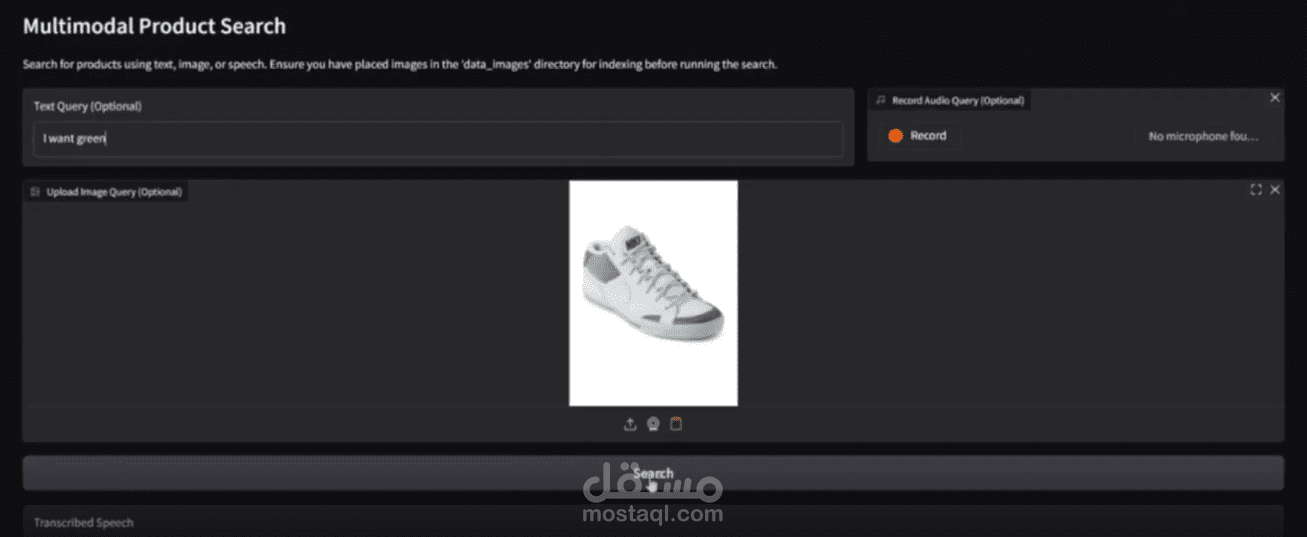
A multimodal AI system that allows text, image, and voice search — powered by CLIP, FAISS, Whisper, and SpeechT5.
Developed in Python using Hugging Face Transformers and Gradio for the interface.
Features
Text & Image Embeddings using OpenAI’s CLIP model
Speech-to-Text with Whisper (via Hugging Face API)
Text-to-Speech with Microsoft SpeechT5
Vector Search powered by FAISS
Sentiment Feedback System to collect and analyze user impressions with DistilBERT
Interactive Gradio Interface for seamless multimodal queries