مشروع التعرف على اللهجات العربية للنص المكتوب
تفاصيل العمل



مشروع التعرف على اللهجات العربية
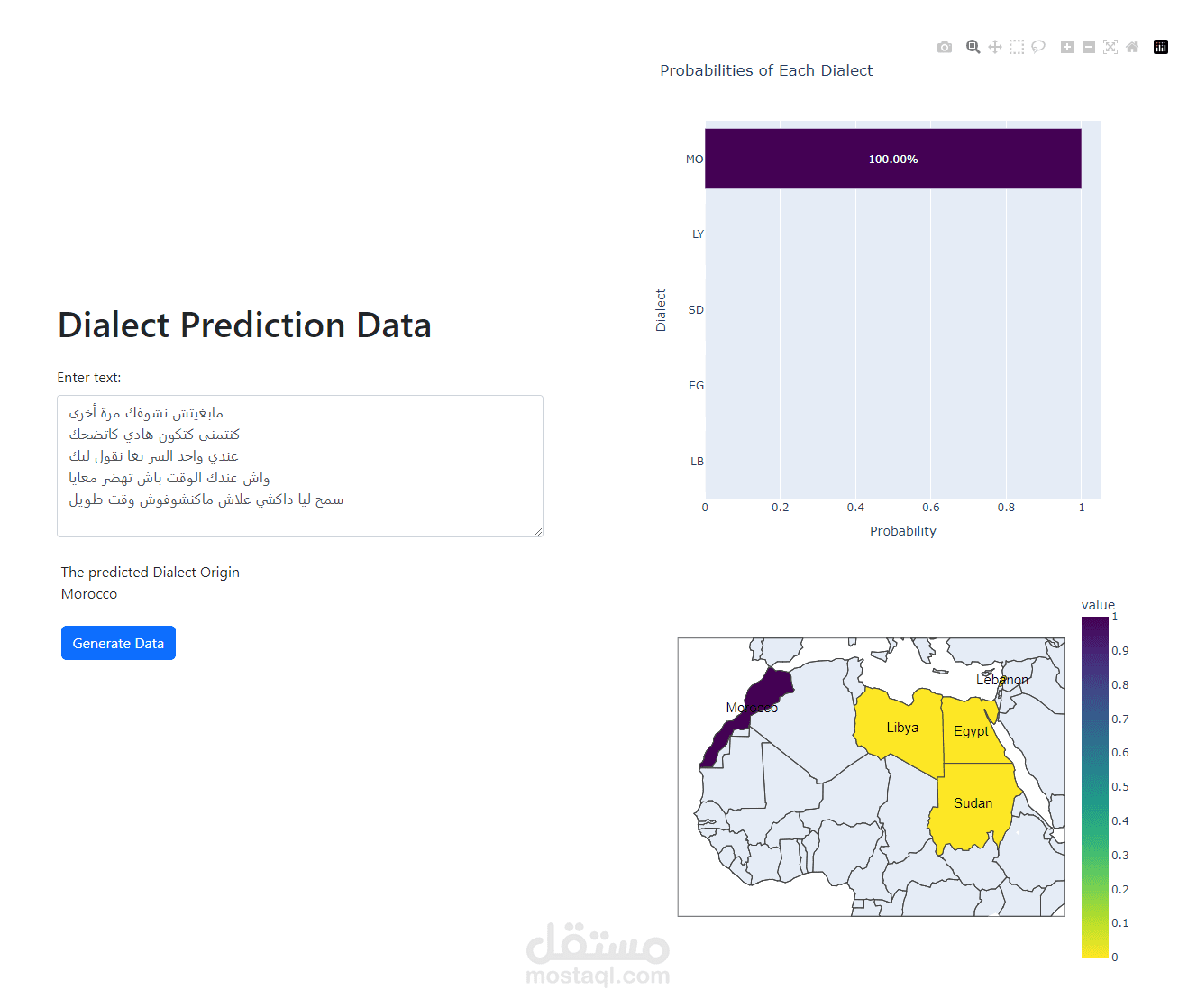
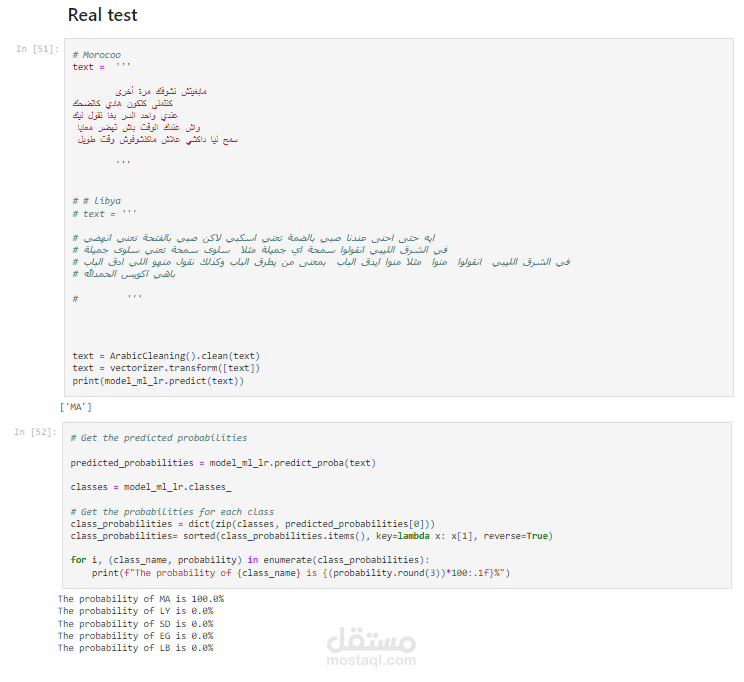
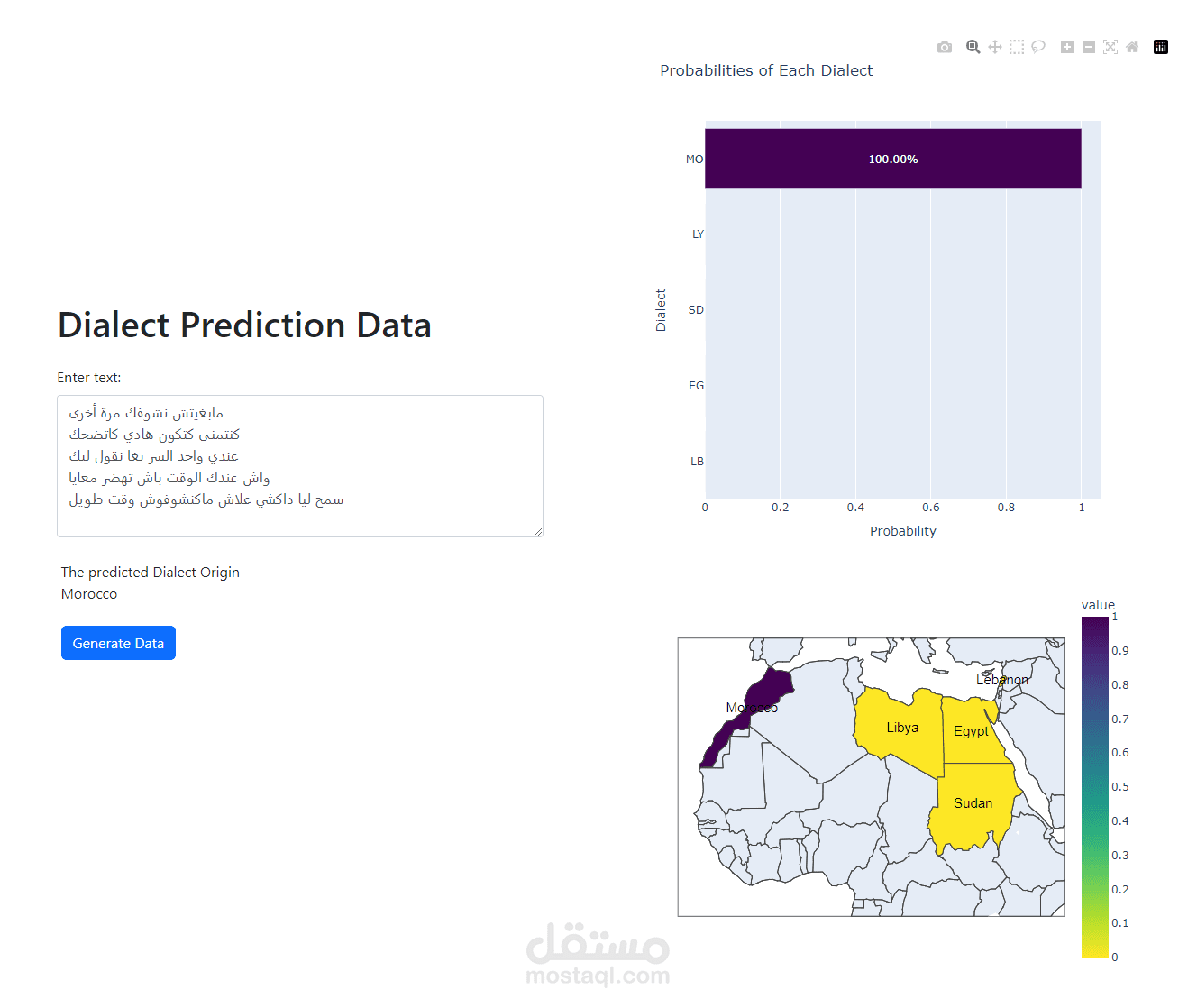
في هذا المشروع يقوم المستخدم بادخال نص باللغة العربية ليقوم النموذج بتحديد اللهجة التي كتب بها النص بالاضافة لتحديد منشا هذه اللهجة و البلدان العربية التي تتحدث بها. يقوم النموذج ايضا باعطاء نسبة لاحتمالية تحدث هذه اللهجة في البلدان المذكورة.
خطوات مشروع التعرف على اللهجات العربية
Arabic_Dialect_Detector_NLP
1. المعالجة المسبقة للنصوص (Preprocessing):
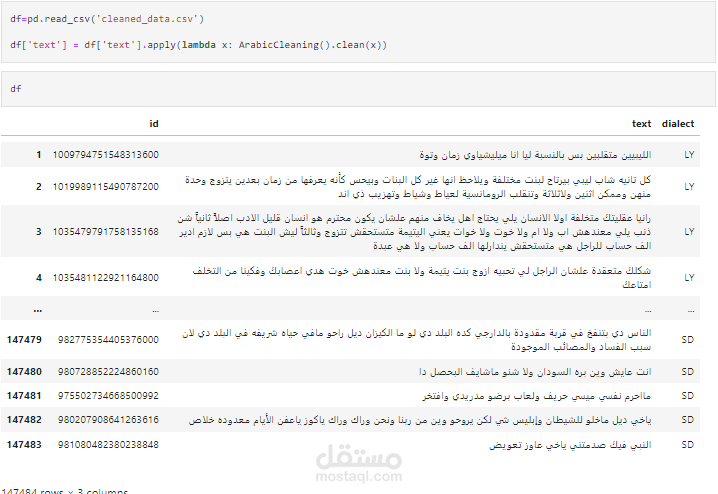
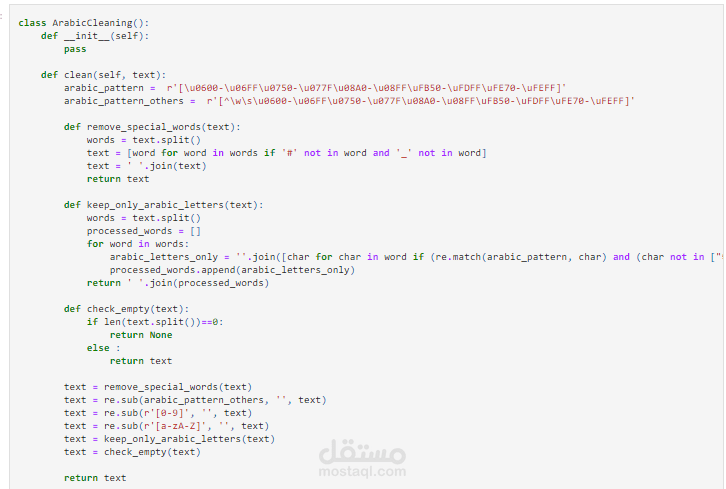
تبدأ العملية بتنظيف البيانات النصية لإعدادها للاستخدام في النماذج. تشمل خطوات المعالجة المسبقة إزالة العلامات الترقيمية، الأرقام، والرموز الخاصة التي قد تؤثر على دقة النموذج. بالإضافة إلى ذلك، يتم إزالة الكلمات غير المفيدة (مثل أدوات الربط) والمعروفة باسم "stop words". كما يتم معالجة الكلمات لجعلها بحروف صغيرة (lowercasing) لتوحيد النصوص.
2. التقطيع إلى رموز (Tokenization):
بعد المعالجة المسبقة، يتم تقسيم النصوص إلى وحدات صغيرة أو "رموز" (Tokens)، وهي الكلمات الفردية أو حتى الأحرف التي تُستخدم كمدخلات للنماذج. يتم استخدام أدوات مثل `NLTK` أو `spaCy` لهذا الغرض، حيث يتم تقسيم النصوص إلى تسلسلات مفهومة من قبل النماذج.
3. نماذج تقطيع الكلمات (Word Embedding Models):
لضمان أن تكون النصوص جاهزة للاستخدام مع نماذج التعلم العميق، يتم تحويل الرموز إلى تمثيلات رقمية. من بين النماذج الشائعة:
- Word2Vec: يمثل الكلمات كمتجهات ضمن فضاء مستمر، ما يمكن النموذج من فهم العلاقات بين الكلمات المختلفة.
- FastText: يشبه Word2Vec لكنه يأخذ بعين الاعتبار تركيب الكلمة، وهو مناسب بشكل خاص للغات مثل العربية حيث تتغير الكلمات بسبب الإعراب.
- BERT و Arabic-BERT: نماذج قائمة على محولات (Transformers) تعطي أهمية للسياق الكامل للكلمة في النص، مما يساعد على فهم أكثر دقة للهجات المختلفة.
4. التدريب باستخدام نماذج تعلم الآلة والتعلم العميق:
- خوارزميات التعلم الآلي التقليدية: مثل الانحدار اللوجستي (LR) وأشجار القرار، حيث يتم تدريبها على البيانات المعالجة مسبقًا.
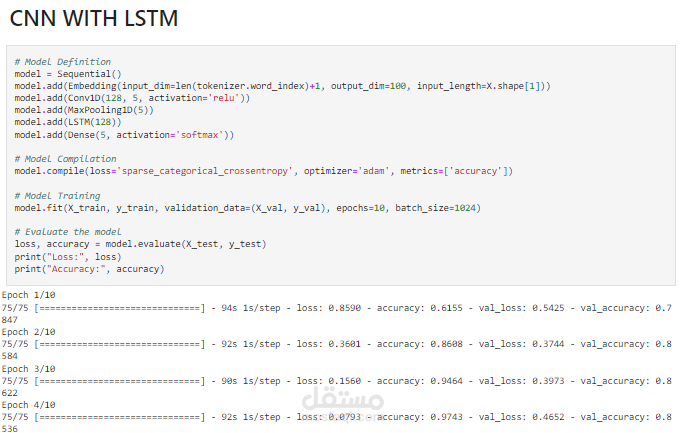
- نماذج التعلم العميق: مثل الشبكات العصبية الالتفافية (CNN) التي تلتقط الأنماط المحلية في النصوص، والشبكات طويلة المدى قصيرة الذاكرة (LSTMs) التي تتعامل مع تسلسلات النصوص الطويلة.
5. النماذج الهجينة:
الجمع بين CNN و LSTM لإنشاء نموذج هجين يستفيد من كلتا الميزتين: اكتشاف الأنماط المحلية باستخدام CNN والتعامل مع تسلسلات طويلة باستخدام LSTM لتحسين دقة التصنيف.
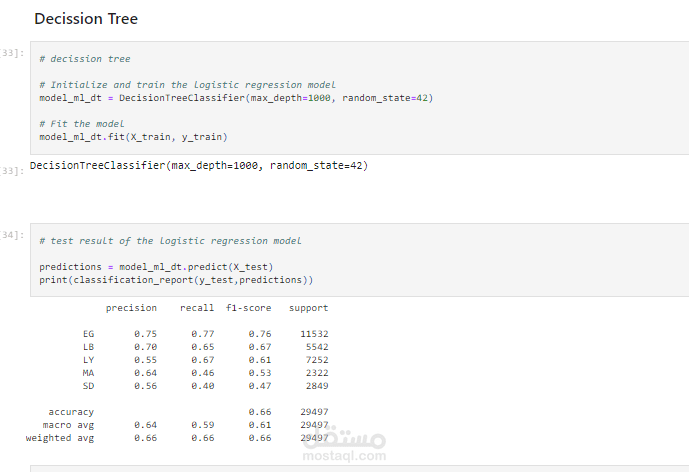
6. التقييم والتحسين:
يتم استخدام بيانات الاختبار لقياس أداء النموذج باستخدام مقاييس مثل الدقة (accuracy)، والتذكر (recall)، والدقة النوعية (precision). بناءً على النتائج، يتم تحسين النموذج من خلال تعديل المعلمات، واختيار نماذج أفضل، واستخدام تقنيات مثل تحسين الوزن (weight regularization) أو إسقاط الوحدة (dropout).