استخراج البيانات باستخدام مكتبة Selenium في Python
تفاصيل العمل

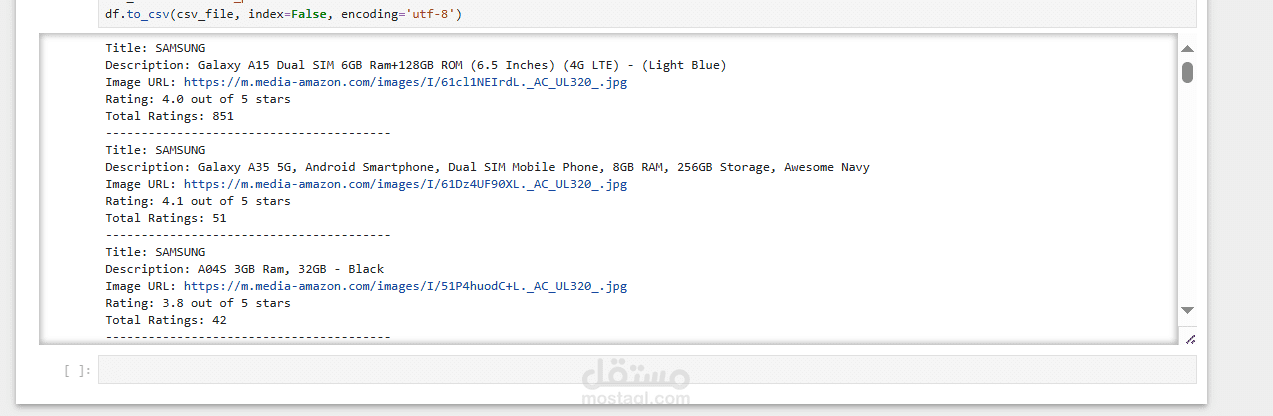
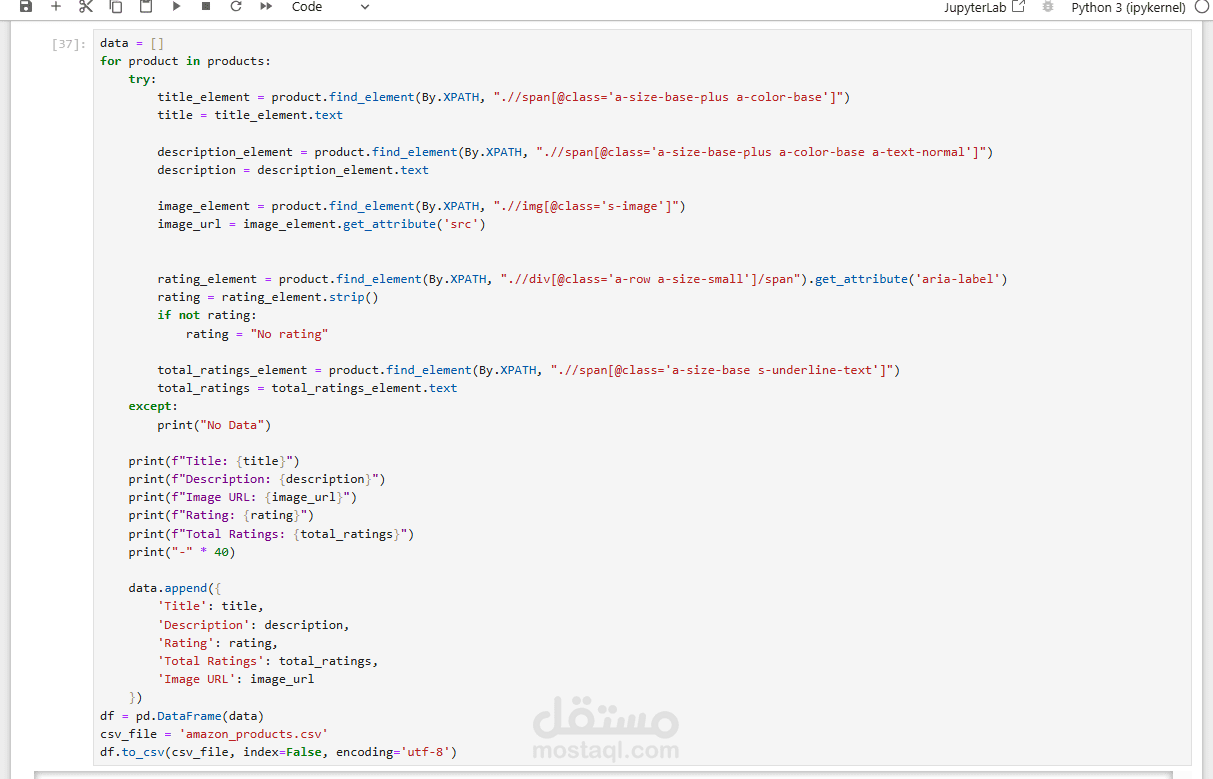

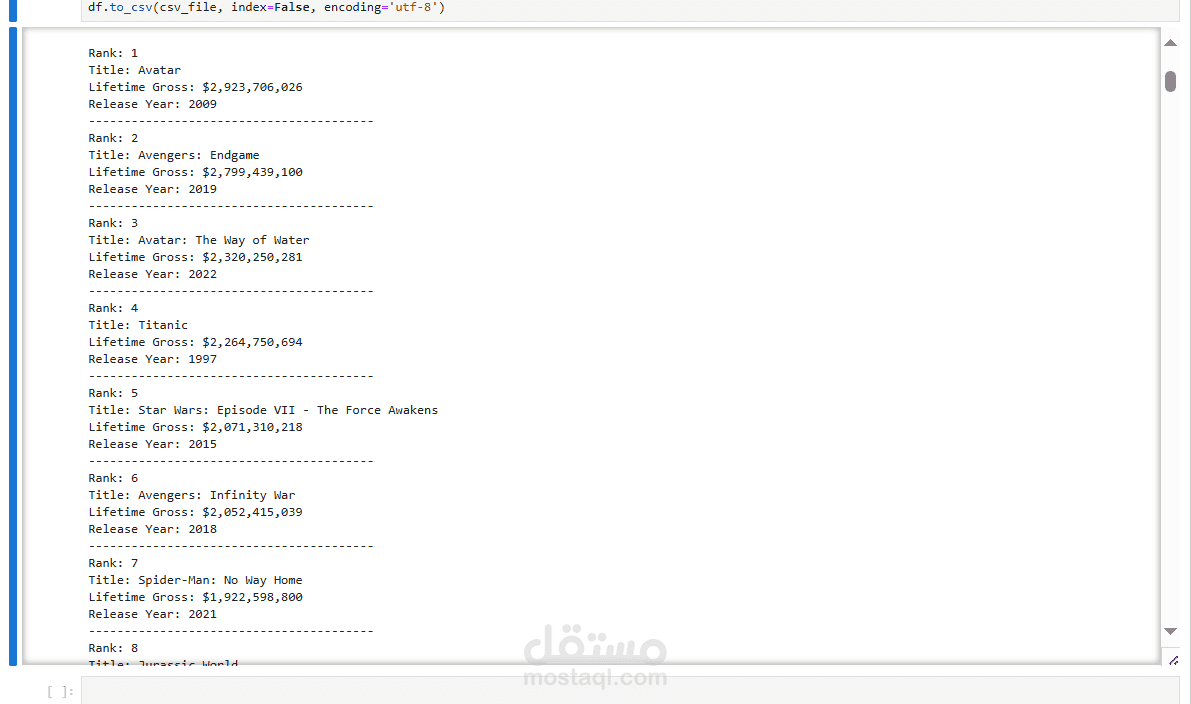
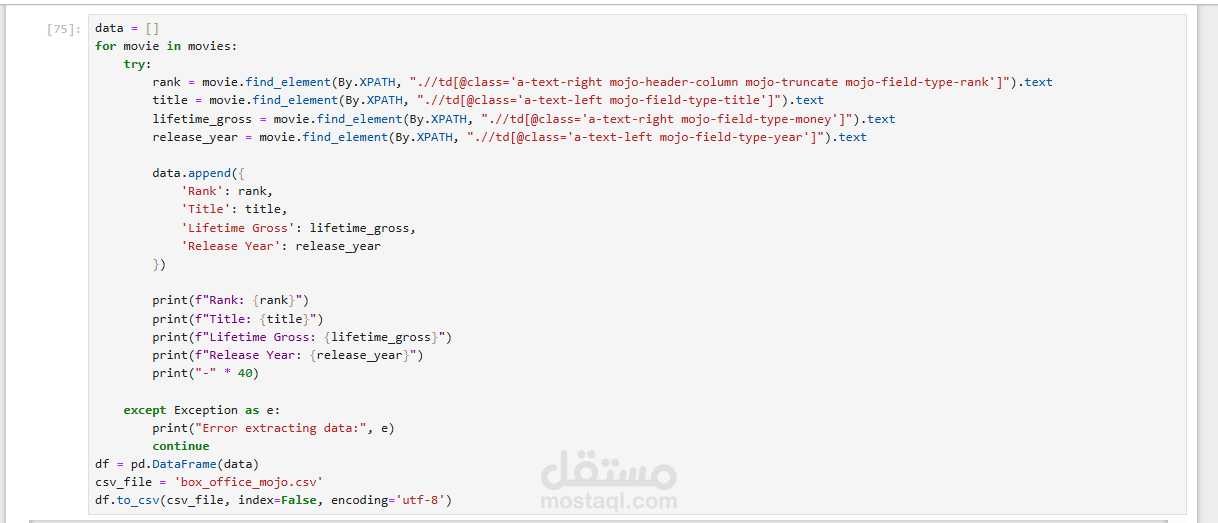
تم تنفيذ هذا المشروع باستخدام مكتبة Selenium في Python لأتمتة عمليات تصفح المواقع واستخراج البيانات منها (Web Scraping). كانت الأهداف الرئيسية للمشروع تتمثل في الوصول إلى بيانات محددة من موقع إلكتروني، استخراجها وتنظيمها لتصبح جاهزة للتحليل أو الاستخدام في مشاريع لاحقة.
مراحل تنفيذ العمل:
تحديد الموقع المستهدف وتهيئة البيئة:
قمت بتحديد الموقع الذي سيتم استخراج البيانات منه، مع مراعاة الالتزام بسياسة الاستخدام الخاصة به.
تهيئة بيئة العمل من خلال تثبيت المكتبات المطلوبة، مثل Selenium وWebDriver الخاص بالمتصفح (مثل ChromeDriver).
كتابة أكواد الأتمتة:
كتبت السكربتات اللازمة للتحكم في المتصفح وتصفح الصفحات المستهدفة.
استخدمت أدوات مثل Xpath لتحديد العناصر المستهدفة داخل الصفحات واستخراج البيانات منها.
تنظيم البيانات:
بعد استخراج البيانات بنجاح، تم تنظيمها في تنسيقات سهلة الاستخدام مثل CSV أو JSON.
تم تنظيف البيانات للتأكد من أنها خالية من الأخطاء والمعلومات غير الضرورية.
المهام التي قمت بها:
إعداد بيئة التطوير وتثبيت جميع المكتبات والأدوات اللازمة.
كتابة أكواد Python باستخدام Selenium لتصفح المواقع واستخراج البيانات.
التعامل مع العناصر الديناميكية والبيانات المعقدة في الموقع.
تنظيف وتنظيم البيانات المستخرجة وحفظها في تنسيقات قابلة للتحليل.
النتيجة النهائية:
تم استخراج البيانات المطلوبة بنجاح من الموقع المستهدف وتحويلها إلى تنسيق منظم وجاهز للتحليل. كانت النتائج دقيقة وتم التأكد من مطابقتها للمعايير المطلوبة. يمكن استخدام البيانات المستخرجة في مشاريع التحليل أو التقارير اللاحقة.
ملفات مرفقة
بطاقة العمل
| اسم المستقل | رغد م. |
| عدد الإعجابات | 0 |
| عدد المشاهدات | 13 |
| تاريخ الإضافة | |
| تاريخ الإنجاز |