التعاون مع عميل حقيقي لاستخراج وتحليل بيانات من بائعي الساعات عبر الإنترنت
تفاصيل العمل
مشروع استخراج البيانات من الويب: جمع بيانات الساعات لشركة ناشئة
نظرة عامة على المشروع:
كان الهدف الرئيسي من هذا المشروع هو استخراج بيانات مفصلة عن الساعات من موقع ويب منافس لشركة ناشئة تعمل في بيع الساعات عبر الإنترنت. طلب العميل عدم ذكر اسم الشركة نظرًا لاهتمامه بالخصوصية. تضمنت البيانات التي تم جمعها مجموعة واسعة من السمات مثل العلامة التجارية، اللون، الوزن، الحجم، الطراز، سنة الإصدار، وما إذا كانت الساعات إصدارات محدودة أم لا. كان الهدف من هذه البيانات هو مساعدة العميل في بناء قاعدة بيانات شاملة للتحليل واتخاذ القرارات الاستراتيجية.
البيانات التي تم جمعها:
تم استخراج البيانات المتعلقة بالساعات والتي تضمنت ميزات متعددة مثل:
تفاصيل المنتج: العلامة التجارية، الطراز، الحجم، اللون، الوزن.
معلومات الإصدار: ما إذا كانت الساعة إصدارًا محدودًا أم لا، وسنة إصدارها.
ميزات إضافية: أي ميزات أو خصائص مميزة ذكرت لكل طراز.
كانت هذه البيانات متاحة للجمهور، مما يعني أنه لم يكن مطلوبًا تسجيل الدخول لعرضها، مما جعلها مناسبة لجمع البيانات عبر تقنيات استخراج البيانات من الويب وفقًا للمبادئ الأخلاقية العامة.
الأدوات والتقنيات المستخدمة:
BeautifulSoup و requests: تم استخدامهما لاستخراج صفحات الويب والحصول على محتوى HTML.
LXML و XPath: تم استخدامهما للتعامل مع بنية صفحات الويب غير المتناسقة، مما سمح باستخراج البيانات بدقة حتى في حالة اختلاف تخطيط الصفحات.
Pandas: استخدمت لتنظيم وتخزين البيانات في تنسيقات منظمة، مما يسهل التلاعب بها وتحليلها.
RegEx و NumPy: تم تطبيقهما لتنظيف البيانات، مثل استخراج أنماط محددة أو قيم رقمية من النص الخام.
Matplotlib و Plotly Express: استخدمتا لإنشاء التصورات البيانية وتوليد التقارير للعميل.
تنظيف البيانات:
في عملية تنظيف البيانات، استخدمت مجموعة من أدوات Regex بالإضافة إلى طرق سلسلة نصوص بسيطة مثل .strip() لتنظيف النصوص. بشكل عام، كانت البيانات نظيفة إلى حد كبير منذ البداية، حسب متطلبات العميل. على سبيل المثال، قمت بإزالة المسافات الزائدة والرموز غير الضرورية ومعالجة التنسيقات غير المتسقة لضمان توحيد البيانات.
التعامل مع البيانات المفقودة:
أثناء عملية استخراج البيانات، كانت بعض السمات مفقودة. بعد التشاور مع العميل، أكد أن بعض السمات في نماذج معينة من الساعات قد تكون مفقودة وهذا كان متوقعًا. كانت هذه القيم المفقودة مقبولة لأنها لم تؤثر على الهدف العام. قام العميل بتقديم قائمة بالأعمدة التي يمكن قبول فقدان بياناتها، موضحًا الحقول التي كانت حاسمة والتي يمكن أن تُترك فارغة.
تخزين البيانات:
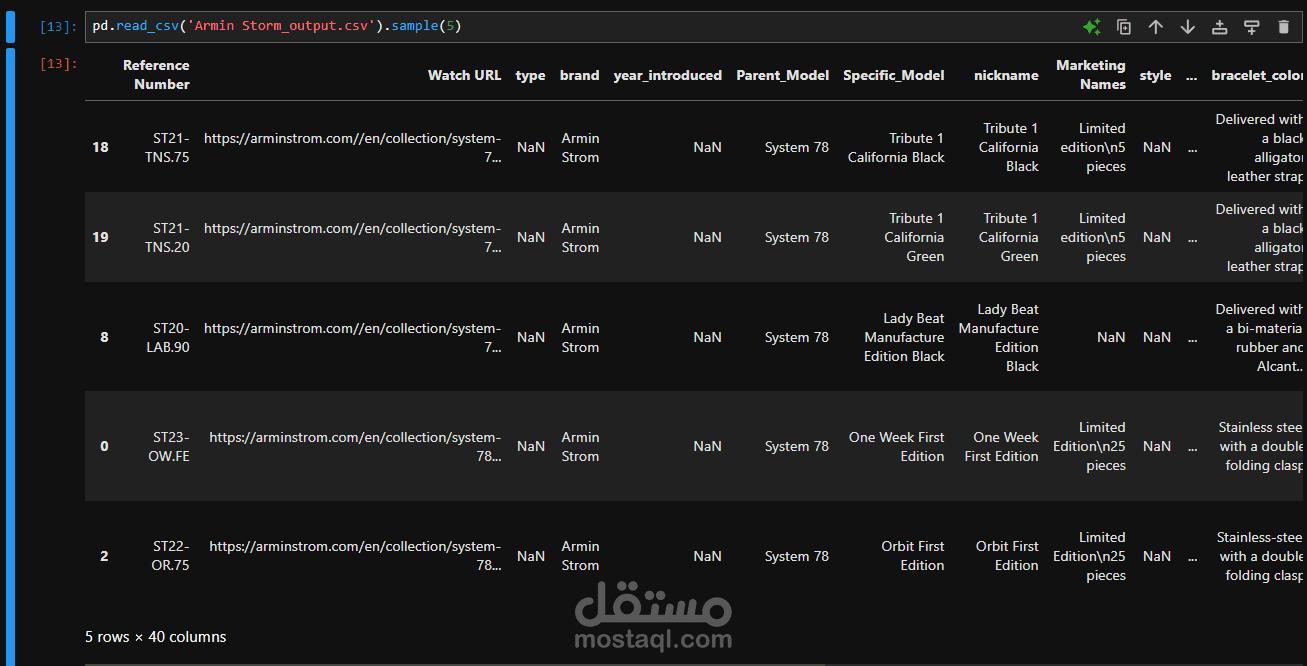
طلب العميل تخزين جميع البيانات في صيغة CSV. نظرًا لأن حجم البيانات لم يكن كبيرًا، لم تكن هناك حاجة لاستخدام أنظمة تخزين معقدة أو قواعد بيانات. بعد تنظيف وتنظيم البيانات، تم تصديرها في ملفات CSV كجزء من التسليم النهائي.
التعامل مع إجراءات منع استخراج البيانات:
على الرغم من أن الموقع لم يتضمن تقنيات متقدمة لمنع استخراج البيانات مثل CAPTCHA، إلا أنني اعتمدت على ممارسات الاستخراج اللطيف، مثل إضافة تأخيرات بين الطلبات باستخدام time.sleep() لتجنب الضغط على الخادم أو التعرض للحظر.
التسليم النهائي:
في نهاية المشروع، قدمت للعميل ما يلي:
1. ملفات CSV تحتوي على البيانات المنظَّمة والمُنظفة.
2. شرائح PowerPoint تتضمن تصورات بيانية، تقدم ملخصًا لخصائص الساعات التي جمعناها.
3. رسوم بيانية وتصورات: تم إنشاؤها باستخدام Matplotlib و Plotly Express، تعرض إحصائيات مختلفة حول البيانات المجمعة، مثل توزيع نماذج الساعات والعلامات التجارية والميزات الفريدة.
4. دفتر Jupyter Notebook: تم تقديمه كوثيقة فنية تشرح الخطوات التي اتبعناها خلال المشروع، من استخراج البيانات وتنظيفها إلى التصور والتحليل النهائي.
كان العميل راضيًا عن التسليمات لأنها قدمت رؤى حول سوق الساعات، مما ساعدهم على اتخاذ قرارات مستنيرة بناءً على عروض المنتجات لدى المنافسين. تم الانتهاء من المشروع في الوقت المحدد وتم دمج البيانات بنجاح في نظام العميل للتحليل المستقبلي.
ملفات مرفقة
بطاقة العمل
| اسم المستقل | أحمد ا. |
| عدد الإعجابات | 0 |
| عدد المشاهدات | 1 |
| تاريخ الإضافة |