تطوير وتنفيذ نموذج معالجة اللغات الطبيعية (NLP) لتصنيف الأسئلة على StackOverflow حسب لغات البرمجة
تفاصيل العمل

نظرة عامة على المشروع:
يتعلق هذا المشروع بهندسة البيانات الضخمة، حيث تم بناء خط أنابيب شامل (end-to-end) لإدارة ومعالجة مجموعات البيانات الكبيرة من StackOverflow، التي يزيد حجمها عن 200 جيجابايت. كانت التحديات الرئيسية مزدوجة: أتمتة خط الأنابيب لجلب البيانات بشكل يومي، وضمان تصنيف موثوق لمنشورات StackOverflow (الأسئلة) باستخدام تعلم الآلة إلى الفئات المناسبة.
بيان المشكلة:
تعامل المشروع مع مهمتين أساسيتين:
1. أتمتة خط الأنابيب: نظرًا لحجم البيانات الكبير، كان من الضروري بناء خط أنابيب قابل للتوسع وأتمتة جلب البيانات وتخزينها في مخزن البيانات (data lake) على منصة Azure بشكل يومي. كان هذا يتطلب تنفيذ خط أنابيب قوي يتعامل مع التحديثات الجديدة دون تدخل يدوي، مما يضمن كفاءة النظام وقدرته على معالجة البيانات الجديدة عند وصولها.
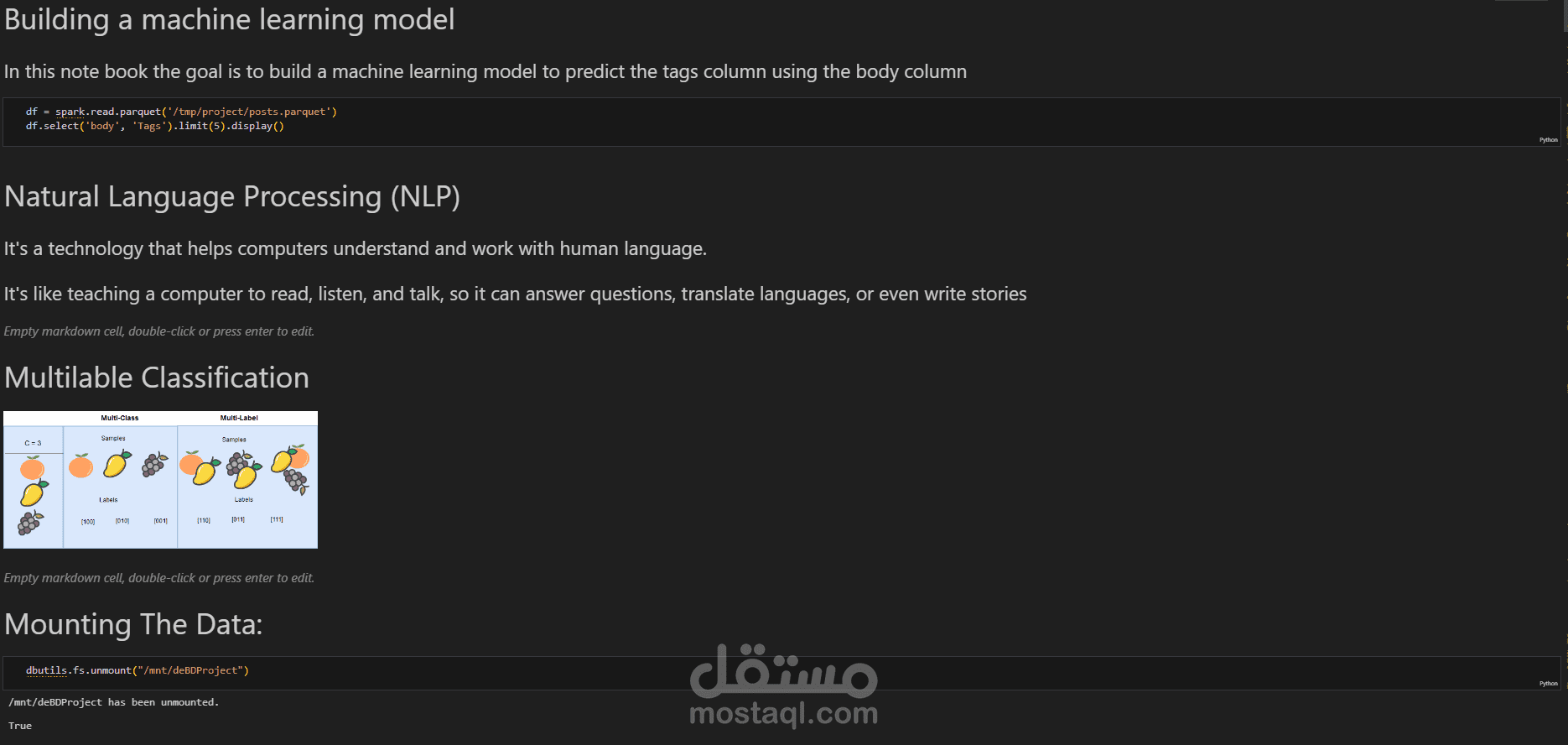
2. تصنيف منشورات التعلم الآلي: التحدي الثاني كان تطوير نموذج تعلم آلي قادر على تصنيف المنشورات (الأسئلة) إلى الفئات المناسبة (الوسوم). تضمن ذلك التعامل مع مشكلة التصنيف متعدد العلامات، حيث يمكن أن ينتمي كل سؤال إلى عدة وسوم. كما تمت معالجة مشكلة البيانات غير المتوازنة من خلال زيادة حجم البيانات وتحسين أداء النموذج.
الأدوات والتقنيات:
تم استخدام مجموعة متنوعة من الأدوات والتقنيات للتعامل مع هذه البيانات الضخمة بكفاءة:
1. Apache Spark: كانت قدرات Spark في المعالجة الموزعة أساسية للتعامل مع مجموعة بيانات StackOverflow الكبيرة (أكثر من 200 جيجابايت). تم استخدام Spark لتنظيف وتحويل هذه البيانات على نطاق واسع استعدادًا للعمليات اللاحقة.
2. Python وPandas:
تم استخدام Pandas في عدة مراحل للتعامل مع البيانات في شكل جداول، خصوصًا مع مجموعات البيانات الصغيرة.
كما تم دمجها في تدفق العمل لزيادة البيانات باستخدام نموذج NLP.AUG المسبق التدريب لتحضير البيانات للتعلم الآلي.
ساهمت Pandas في تكاملها السلس مع مكتبة scikit-learn في تسهيل تدريب النموذج وتقييمه.
3. scikit-learn:
استخدمت مكتبة scikit-learn لنمذجة تعلم الآلة، حيث تم استخدام LinearSVC ضمن إطار عمل One-vs-Rest Classifier لحل مشكلة التصنيف متعدد العلامات.
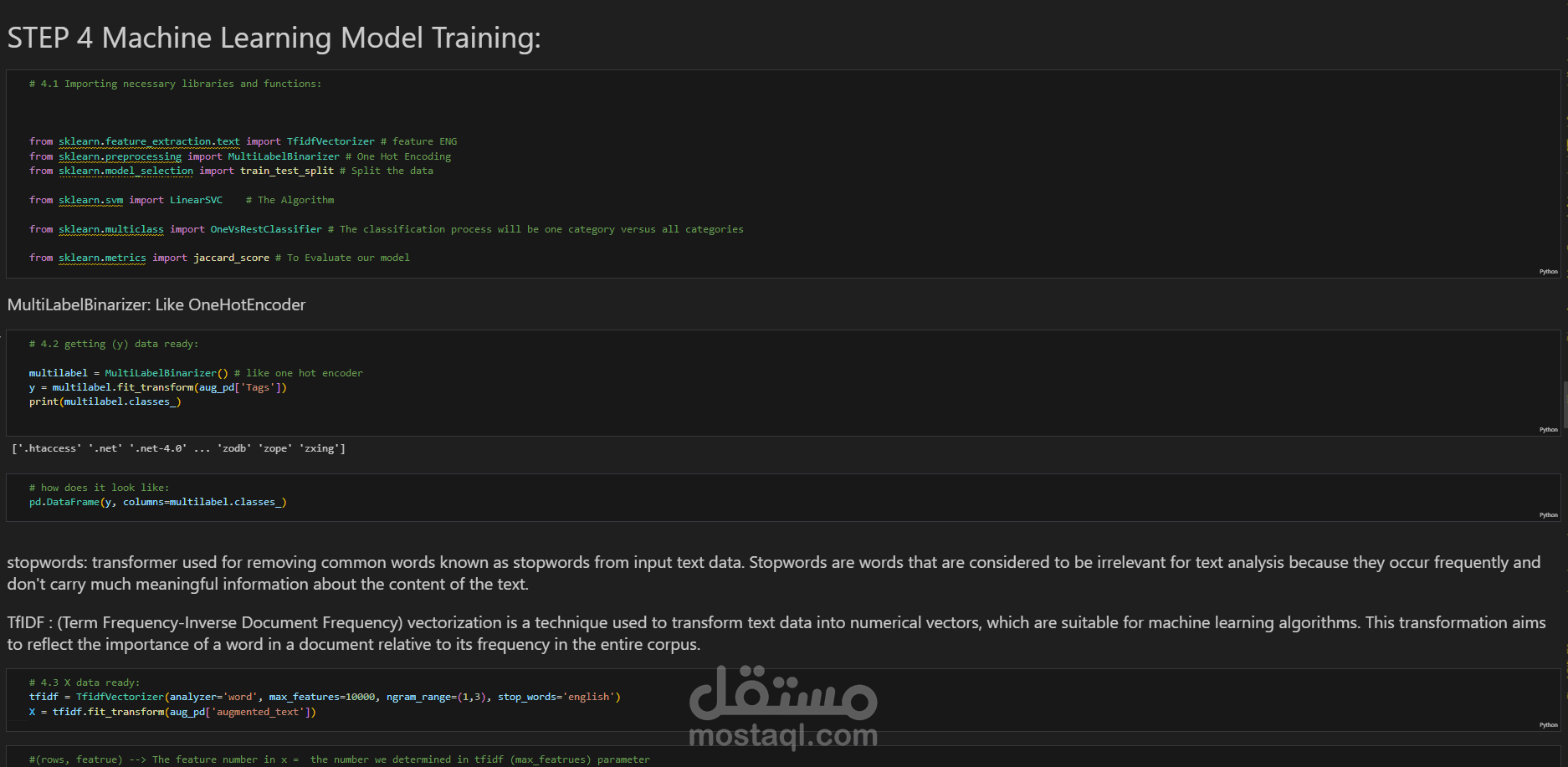
استخدمت أداة TF-IDF Vectorizer لاستخراج الخصائص وتحويل النصوص النظيفة إلى تمثيل رقمي مناسب لتدريب النموذج.
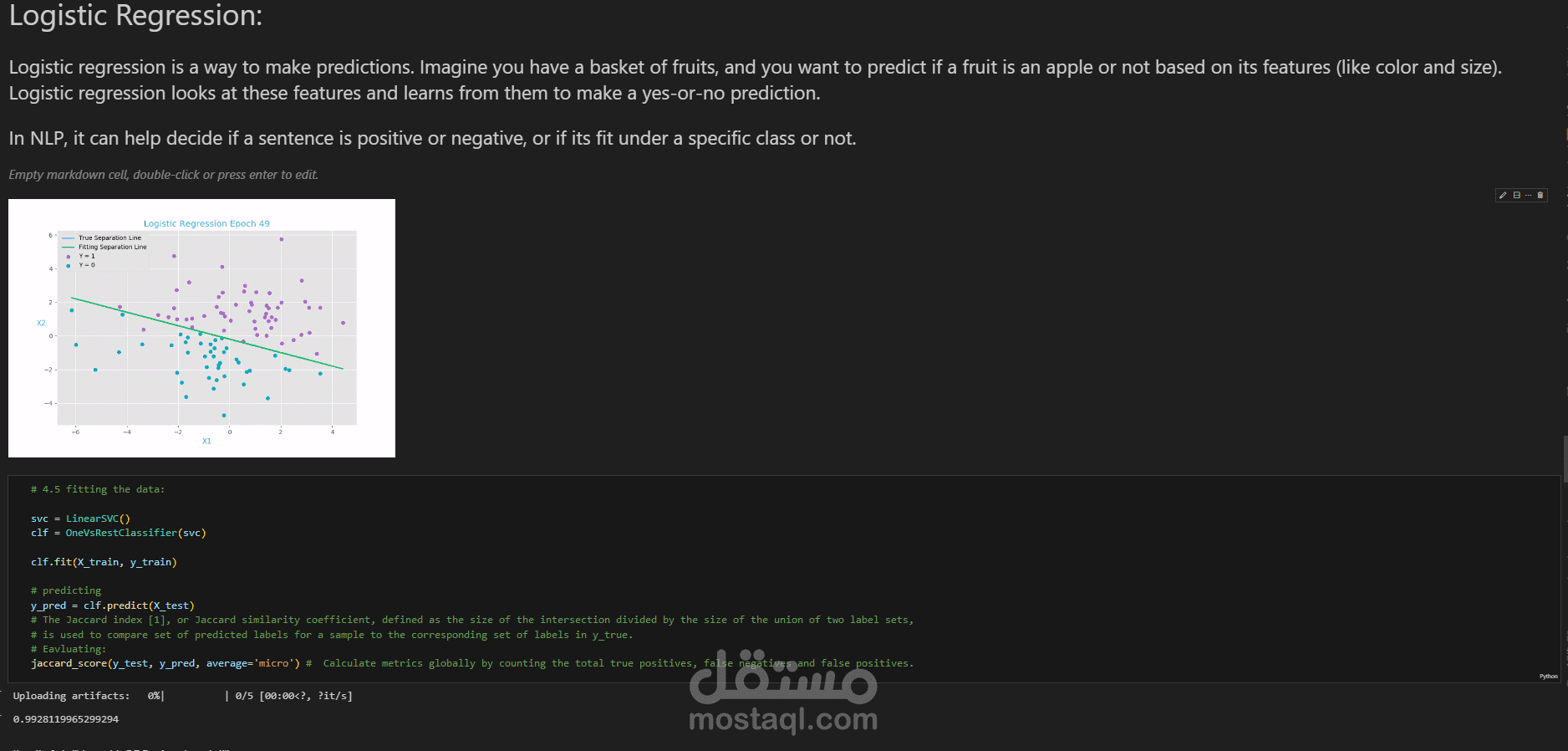
تم تقييم أداء النموذج باستخدام Jaccard score (النسخة المصغرة micro)، وهو مقياس يقيس التشابه بين الوسوم المتوقعة والحقيقية، مما يوفر تقييماً دقيقاً لأداء النموذج في التنبؤ بالعلامات.
4. Microsoft Azure:
تم بناء المشروع على منصة Microsoft Azure، حيث تم استخدام Azure Blob Storage كمخزن بيانات (data lake) لتخزين البيانات الخام والمعالجة.
تم دمج خط الأنابيب مع Azure لضمان التوسع والموثوقية في التعامل مع كميات ضخمة من البيانات.
5. PySpark: استخدمت PySpark كواجهة لـ Spark ضمن بيئة Python، مما سهل تنظيف وتحويل مجموعات كبيرة من البيانات النصية. هذا ساعد على التكامل السلس بين Spark DataFrames ومكتبات Python الأخرى مثل Pandas.
سير العمل:
1. جمع وتخزين البيانات:
تم جمع البيانات من مصدر بيانات StackOverflow المتاحة على Kaggle وتخزينها في BigQuery. نظرًا لحجم البيانات الكبير، تم استخدام Spark لمعالجة البيانات بكفاءة.
تم تصميم خط الأنابيب ليقوم بجلب بيانات جديدة يوميًا وتخزينها في Azure Blob Storage (data lake)، مما يضمن قدرة النظام على التوسع ومعالجة التحديثات المستمرة.
2. معالجة البيانات واستخراج الخصائص:
تم تصفية البيانات للتركيز فقط على الأسئلة الضرورية لمهمة التصنيف متعدد العلامات.
تم تنظيف النصوص من الضوضاء مثل الروابط والمسافات الزائدة والمحتويات غير النصية باستخدام التعابير العادية وإزالة الكلمات الشائعة.
لاستخراج الخصائص، تم استخدام أداة TF-IDF vectorizer بنطاق n-gram يتراوح بين 1 و 3 وتم تحديد عدد الخصائص القصوى بـ 10,000 لضمان التقاط النموذج للكلمات وتركيبات الكلمات ذات الصلة.
3. زيادة البيانات:
نظرًا لوجود 940 صفًا فقط و1,061 علامة مميزة، كانت البيانات المحدودة تمثل تحديًا في تدريب النموذج. للتغلب على هذا، تم استخدام نموذج NLP.AUG لزيادة البيانات، مما زاد عدد الصفوف إلى 9,400، مما ساعد في تحسين تعلم النموذج من البيانات.
4. نموذج التعلم الآلي:
استخدم LinearSVC مع إستراتيجية One-vs-Rest لتصنيف الأسئلة بناءً على العلامات المتعددة.
تم تقييم النموذج باستخدام Jaccard score (micro)، الذي يقيس التشابه بين العلامات المتوقعة والحقيقية. حقق النموذج Jaccard score قدره 0.992، مما يشير إلى دقة عالية جدًا في التنبؤ بالعلامات الصحيحة لكل سؤال.
خط أنابيب end-to-end:
بعد تدريب نموذج التعلم الآلي، كانت الخطوة الأخيرة هي دمجه في خط الأنابيب. يعمل النظام كالتالي:
1. الجلب اليومي للبيانات: يتم جلب البيانات الجديدة يوميًا من المصدر وتخزينها في Azure Blob Storage.
2. المعالجة الآلية: يقوم خط الأنابيب تلقائيًا بتنظيف وتحويل وزيادة البيانات عند وصولها إلى النظام.
3. التصنيف والتخزين: يقوم نموذج التعلم الآلي بتصنيف المنشورات إلى الوسوم المناسبة، وتُحفظ النتائج للتحليل لاحقًا.
ملفات مرفقة
بطاقة العمل
| اسم المستقل | أحمد ا. |
| عدد الإعجابات | 0 |
| عدد المشاهدات | 2 |
| تاريخ الإضافة |