استخراج النصوص من الملفات والصور باستخدام: Tesseract OCR و Ghostscript
تفاصيل العمل
استخراج النصوص من المفات والصور باستخدام اداتي: Tesseract OCR و Ghostscript
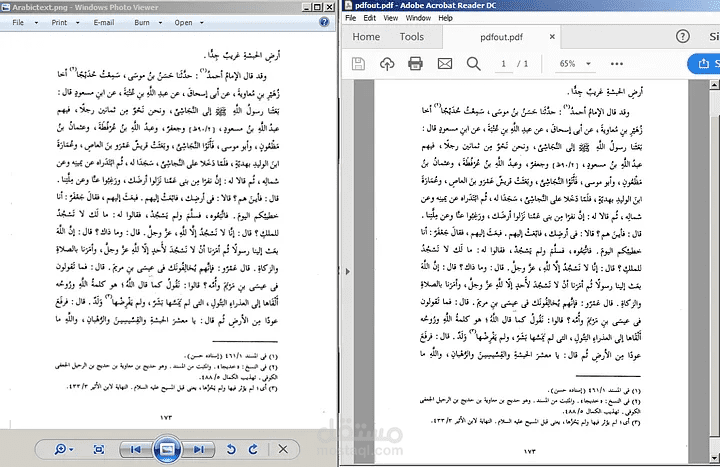
قمت بتطوير حل قوي للتعرف الضوئي على الحروف (OCR) باستخدام مكتبة Tesseract OCR و Ghostscript، مدمجة مع سكربت شيل لمعالجة ملفات PDF. يتميز هذا المشروع بقدرته على تحويل مستندات PDF إلى صور ثم استخراج النصوص منها بدقة، مع دعم كامل للغات العربية والإنجليزية.
الميزات الرئيسية:
- تحويل PDF إلى صور: استخدمت Ghostscript لتحويل ملفات PDF إلى صور عالية الجودة، مما يضمن دقة استخراج النصوص.
- استخراج النصوص عبر OCR: اعتمدت على Tesseract OCR لاكتشاف واستخراج النصوص من الصور المولدة، مع دعم للغتين العربية والإنجليزية، مما يجعل المشروع مرنًا للتعامل مع المستندات متعددة اللغات.
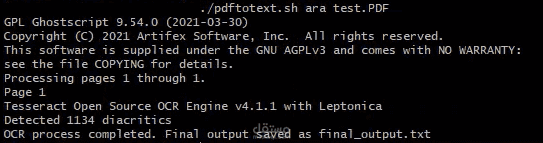
- أتمتة باستخدام سكربت شيل: قمت بإنشاء سكربت شيل يقوم بأتمتة العملية بالكامل. من خلال توفير مسار الملف لملف PDF، يتولى السكربت التحويل واستخراج النصوص، مع إخراج النتائج بصيغة سهلة الاستخدام.
- دعم متعدد اللغات: تم ضمان أن عملية OCR تكتشف وتستخرج النصوص بدقة باللغتين العربية والإنجليزية، مما يلبي احتياجات المستندات المكتوبة بهذه اللغات.
التقنيات المستخدمة:
- Tesseract OCR: للتعرف الضوئي على الحروف واستخراج النصوص.
- Ghostscript: لتحويل ملفات PDF إلى الصور المناسبة لمعالجة OCR.
- سكربت شيل: لأتمتة العملية وتبسيط سير العمل وضمان سهولة الاستخدام.
التحديات التي تم التغلب عليها:
- قمت بتكوين مكتبة Tesseract OCR بنجاح للتعامل مع النصوص المعقدة باللغة العربية جنبًا إلى جنب مع اللغة الإنجليزية، متغلبًا على التحديات الخاصة بتعرف النصوص حسب اللغة.
- تحسين عملية التحويل للحفاظ على جودة الصور، وهو أمر بالغ الأهمية للحصول على نتائج دقيقة من OCR.
يُظهر هذا المشروع قدرتي على دمج أدوات وتقنيات مختلفة لإنشاء نظام OCR وظيفي وفعال، مع التعقيد الإضافي لدعم اللغات المتعددة. يعرض هذا المشروع مهاراتي في الأتمتة، التعرف على النصوص، ومعالجة المستندات في بيئة Unix/Linux.
بطاقة العمل
| اسم المستقل | Abdulrahman M. |
| عدد الإعجابات | 0 |
| عدد المشاهدات | 15 |
| تاريخ الإضافة | |
| تاريخ الإنجاز |