Data Warehouse with Redshift
تفاصيل العمل


Project Overview
This project aimed to enhance the analysis capabilities of a music streaming platform by migrating user and song data to the cloud and implementing a data warehouse infrastructure. The core objectives were to improve data accessibility, scalability, and query performance.
Implementation Stages
1. Data Acquisition and Storage:
Identified and prepared raw song and user activity data in JSON format.
Uploaded data to Amazon Simple Storage Service (S3) buckets for secure and scalable storage.
Organized data within S3 buckets for efficient retrieval based on file structure (e.g., partitioning by year and month for log data).
2. Data Warehouse Infrastructure Setup:
Created an Amazon Redshift cluster as the target data warehouse for optimized analytical workloads.
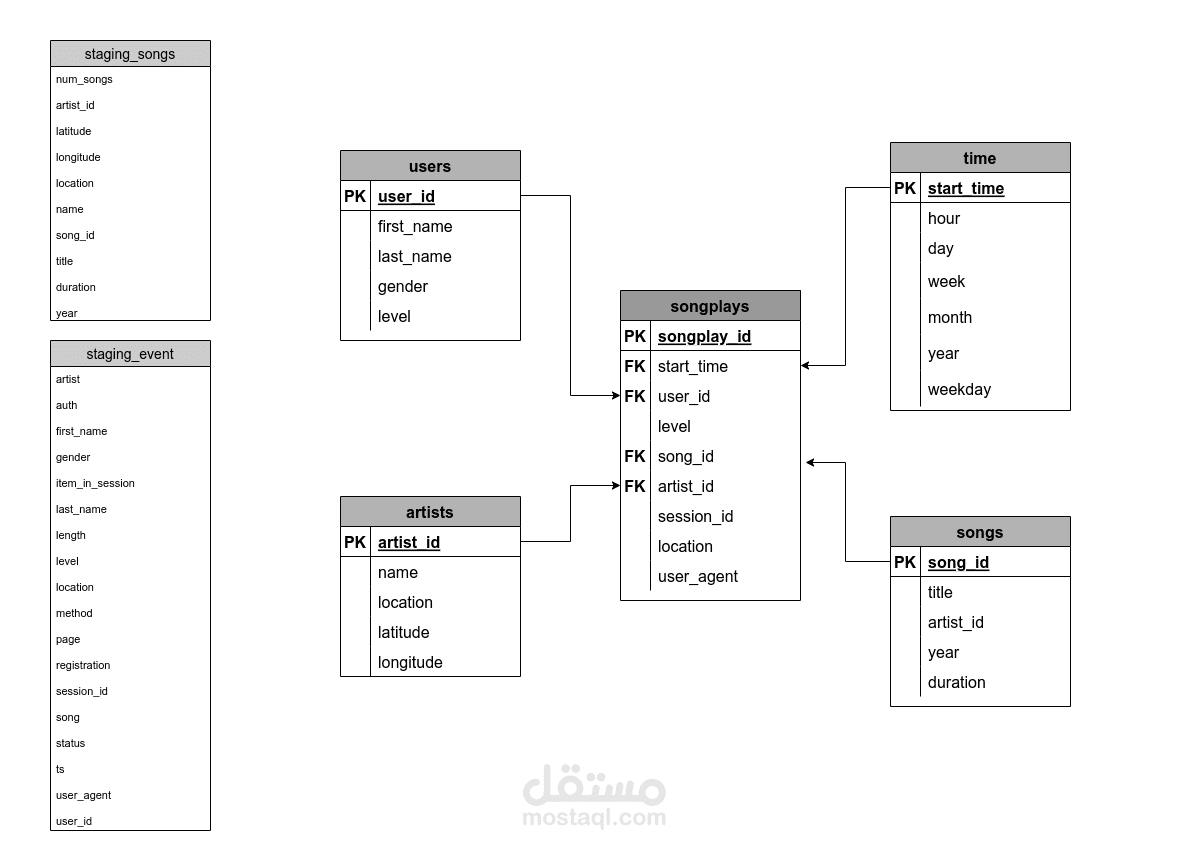
Designed a star schema to model the data, consisting of a fact table (songplays) and four dimension tables (users, songs, artists, and time).
Developed SQL scripts to create the necessary tables within the Redshift database.
3. ETL Pipeline Development:
Created Python scripts to automate the data extraction, transformation, and loading (ETL) process.
Implemented logic to extract data from S3 buckets based on specified file paths and formats.
Performed data cleaning, transformation, and normalization as required to align data with the target schema.
Loaded transformed data into staging tables in Redshift for intermediate processing.
Developed SQL queries to populate the final fact and dimension tables from the staging area.
4. Data Loading and Validation:
Executed the ETL pipeline to transfer data from S3 to the Redshift data warehouse.
Implemented data quality checks to ensure data integrity and accuracy during the loading process.
Verified data consistency and completeness by running exploratory queries on the loaded data.
Final Outcome
The project successfully migrated user and song data to the cloud on Amazon S3. A robust data warehouse infrastructure was established on Amazon Redshift, utilizing a star schema for efficient query performance. The ETL pipeline effectively extracted, transformed, and loaded data into the data warehouse. The final outcome is a scalable and optimized data platform that enables in-depth analysis of user behavior and music consumption patterns.