Data Modeling with Postgres
تفاصيل العمل

Project Overview
This project aimed to enhance the analysis capabilities of a music streaming platform by migrating user and song data to the cloud and implementing a data warehouse infrastructure. The core objectives were to improve data accessibility, scalability, and query performance.
Implementation Stages
1. Data Acquisition and Preprocessing:
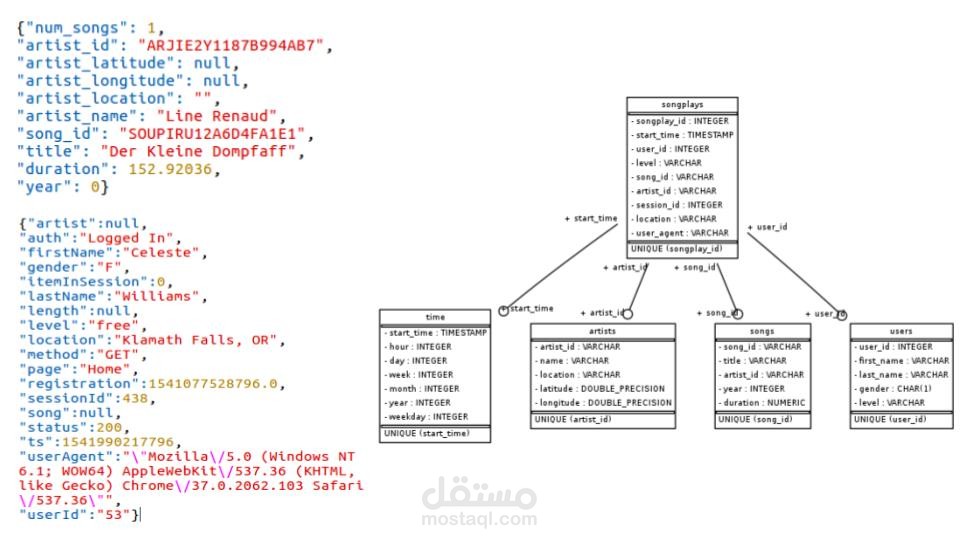
Data Source: Two directories containing JSON files were used for analysis:
song_data: This directory contains a subset of real data from the Million Song Dataset. Each JSON file holds metadata about a song, including its artist. Files are further partitioned by the first three letters of each song's track ID for efficient data access.
log_data: This directory stores log files, also in JSON format. These files were generated by an event simulator based on the songs in the song dataset. They simulate user activity logs on a music streaming app based on pre-configured scenarios. Log files are partitioned by year and month for easier time-based analysis.
2. Data Warehousing and Optimization:
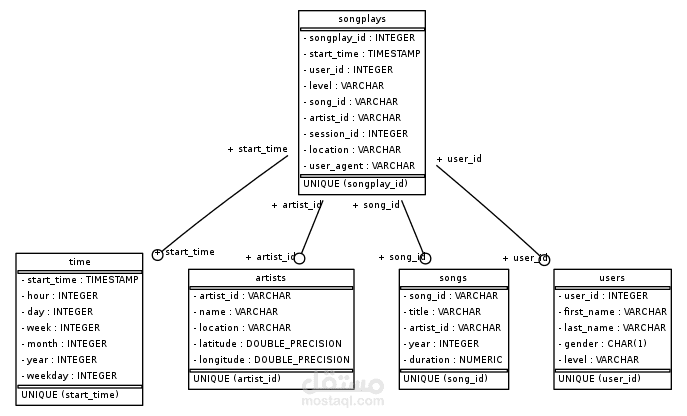
Star Schema Design: A relational database model was designed using a star schema. This schema includes:
Fact Table (songplays): This table stores the core data about song plays, including user interactions.
Dimension Tables (4): These tables provide additional details related to users, songs, artists, and time periods. Each dimension table is linked to the fact table for comprehensive analysis.
Query Optimization: The project focused on optimizing queries used for analyzing song plays. This involved creating an efficient database schema and implementing an Extract, Transform, Load (ETL) pipeline.
3. ETL Pipeline Development:
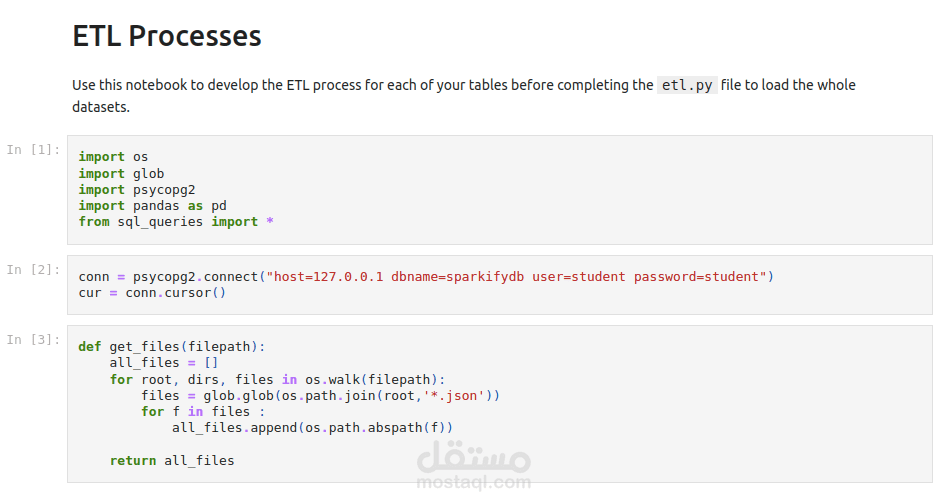
ETL Process: The ETL process is documented step-by-step in two resources:
etl.ipynb Jupyter notebook: This notebook provides a detailed explanation of the ETL process in a user-friendly, interactive format.
etl.py Python script: This script contains the Python code for the ETL pipeline, which automates the data extraction, transformation, and loading steps.
Data Transformation: During the ETL process, the data from log files and song metadata may need to be cleaned, filtered, or transformed to conform to the structure of the database tables.
4. Database Interaction:
SQL Queries: Structured Query Language (SQL) queries were written specifically for the PostgreSQL database engine. These queries allow for efficient retrieval and analysis of user activities based on songs and user interactions stored in the database.
Final Outcome:
This project provides a complete solution for analyzing user activities in a music streaming app. It includes a well-designed star schema database, an optimized ETL pipeline, and powerful SQL queries for querying the data and gaining insights into user behavior.