Arabic proverb recommendation
تفاصيل العمل
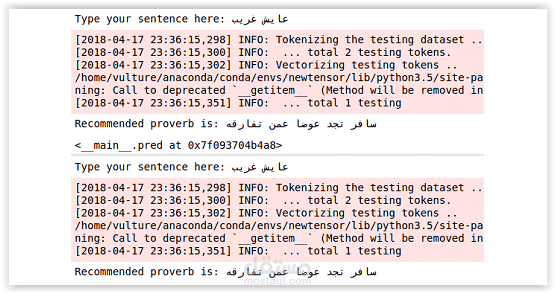
We collected data from twitter which is in the context of the proverb and not including the proverb itself, then made clean and preprocessing on the data . We run our classifier and reached to accuracy over 65% and we are currently improving the model.
بطاقة العمل
| اسم المستقل | محمد ع. |
| عدد الإعجابات | 0 |
| عدد المشاهدات | 252 |
| تاريخ الإضافة | |
| تاريخ الإنجاز |