AI Learn to play a game
تفاصيل العمل

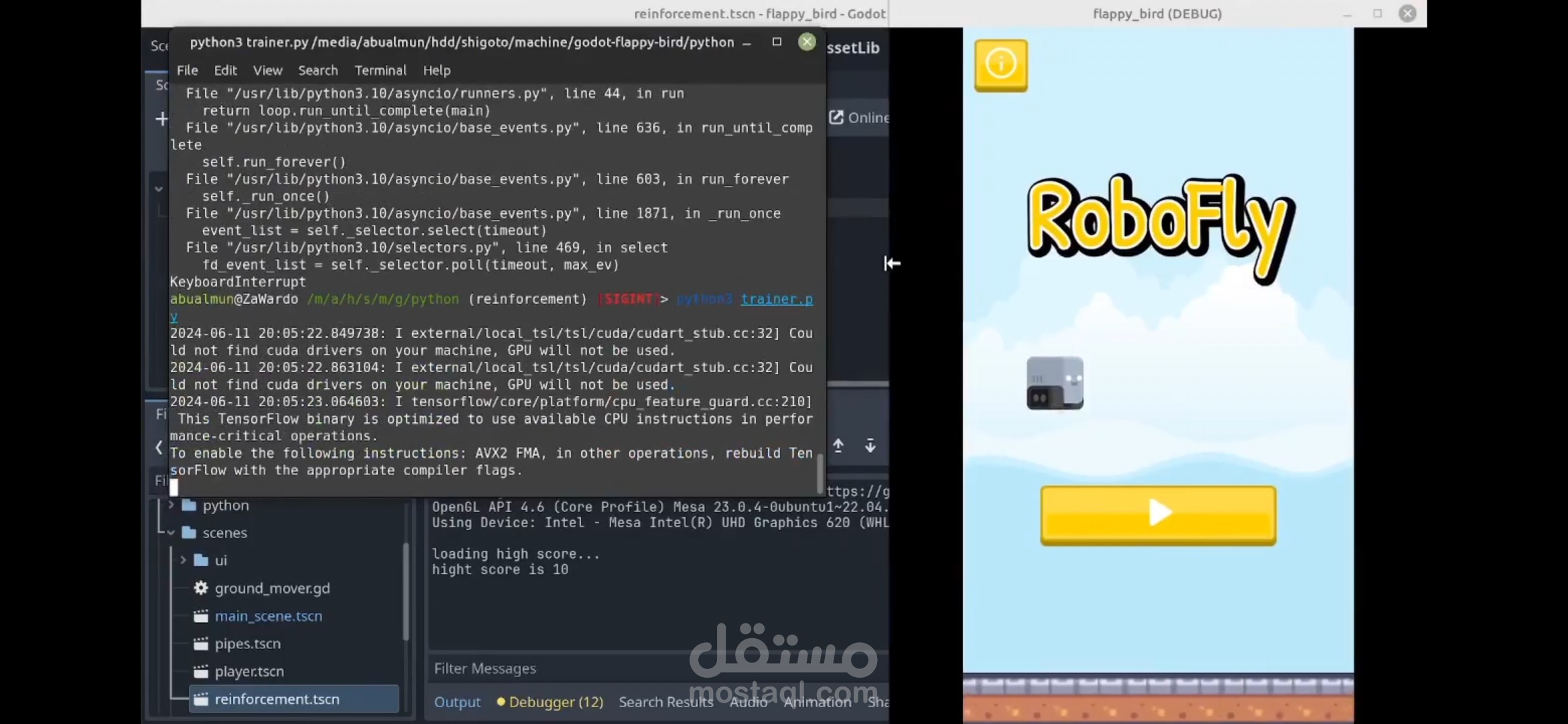
مشروع تصميم مودل ذكاء اصطناعي يتعلم من أخطائه ويتحسن في لعب أي لعبة إذا تمت التعديلات الصحيحة.
يستخدم المشروع تقنية ال Reinforcement Learning بخوارزمية Q-learning.
تم ربط اللعبة في برنامج Godot مع برنامج بايثون عن طريق سيرفر محلي بتقنية socket، ومن ثم إضافة نظام مكافأة وعقاب تقيّم حسب سلوك الAI في اللعب وترسل إليه ليفهم عن طريقها جودة أدائه في اللعبة.
وتعمل الخوارزمية بعد ذلك على تجربة أفكار جديدة ومقارنتها مع الأخطاء القديمة ليصبح التعلم أكثر دقة كلما زادت فترة التدريب.
تم تجربته مع لعبة flappy bird.