data_processing python
تفاصيل العمل
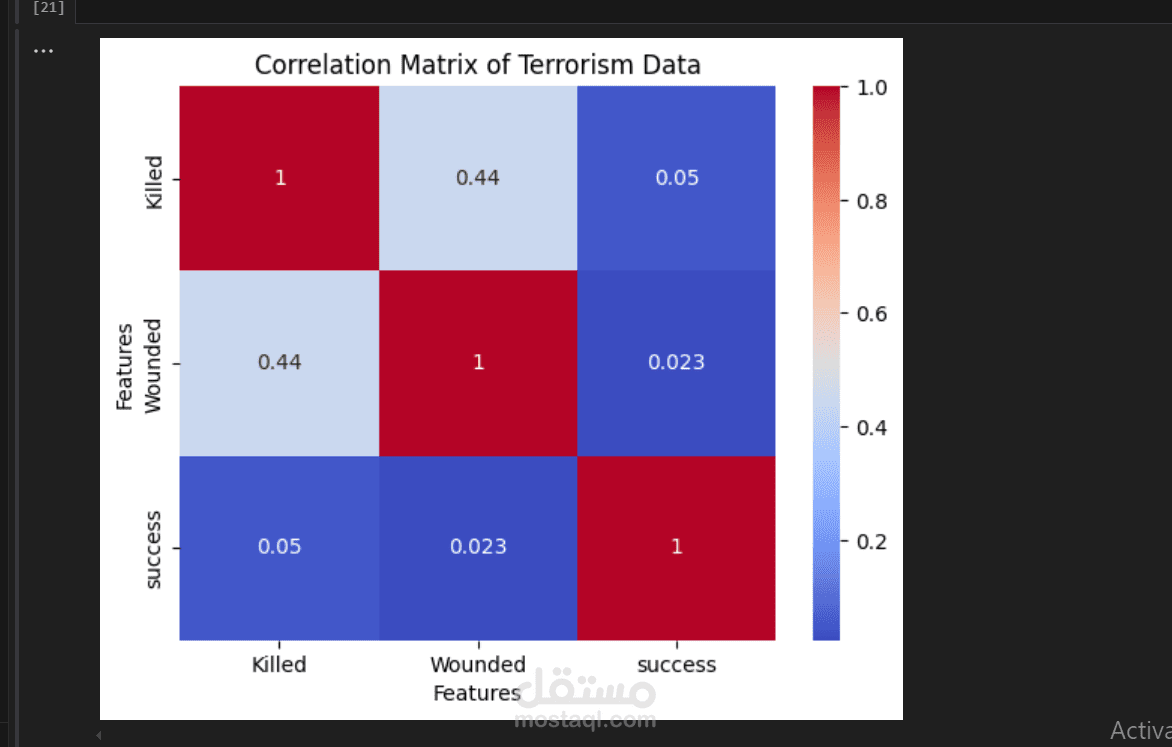
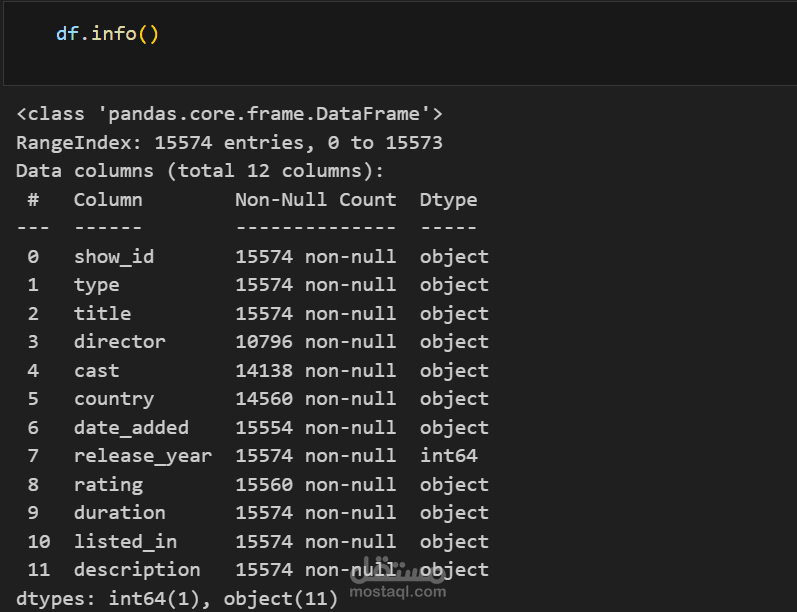
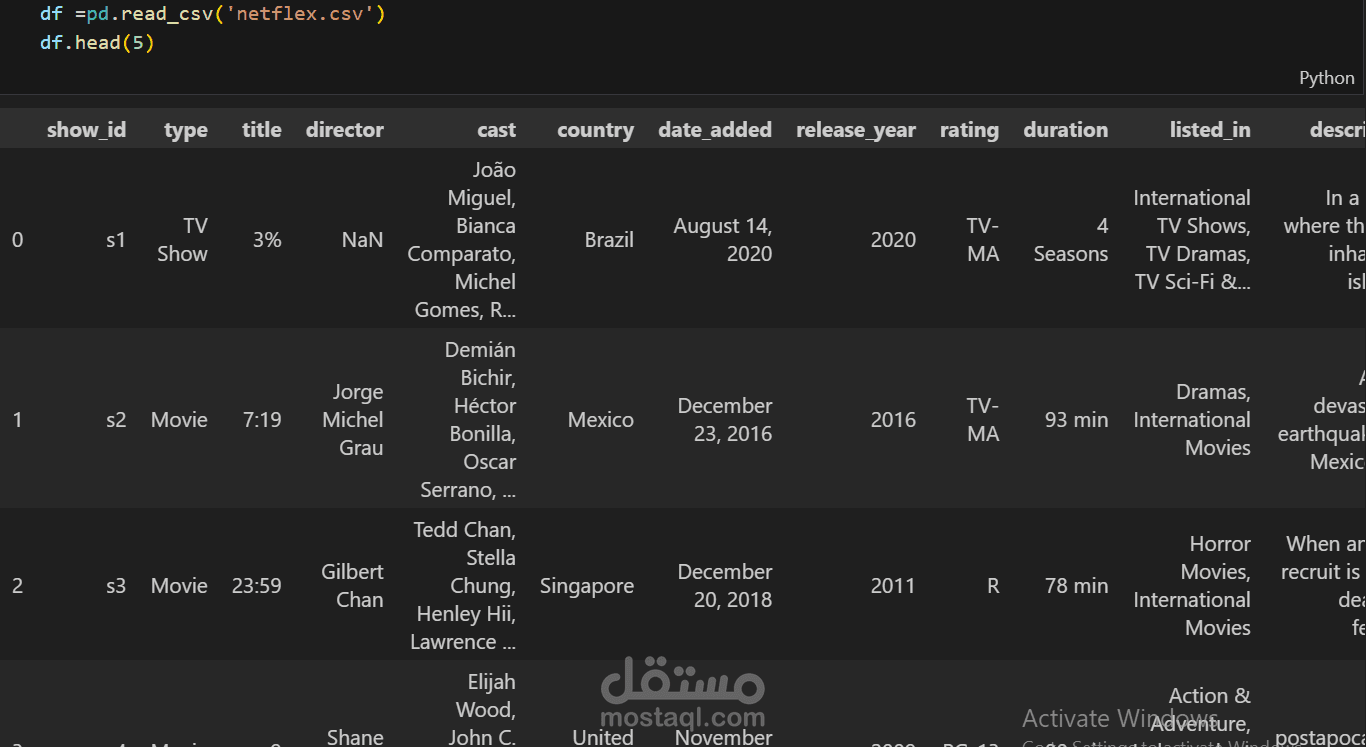
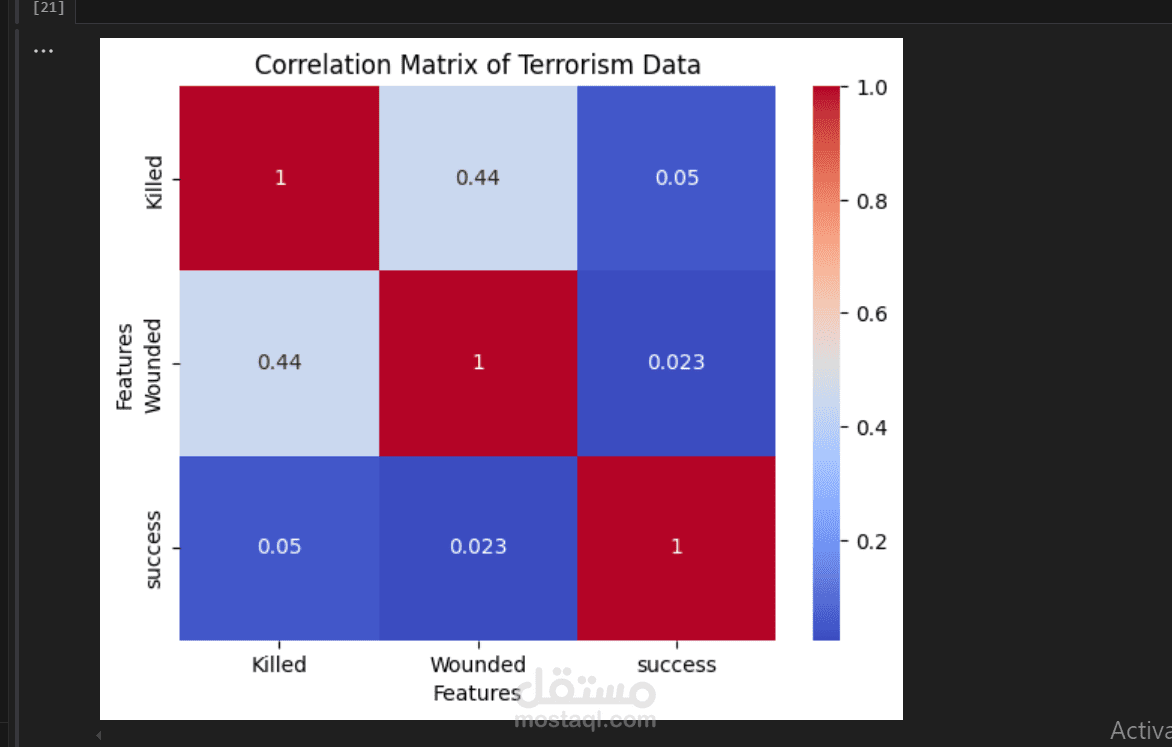
A data preprocessing template in Python typically includes common steps to prepare your data for analysis or machine learning tasks. Here's a template that covers the essential data preprocessing steps:
python
Copy code
# Import necessary libraries
import numpy as np
import pandas as pd
from sklearn.preprocessing import StandardScaler, LabelEncoder
from sklearn.model_selection import train_test_split
# Load your dataset
data = pd.read_csv('your_dataset.csv')
# Step 1: Handling Missing Data
# Check for missing data
missing_data = data.isnull().sum()
# Handle missing data (you can choose different strategies)
# Example: Fill missing numerical data with the mean
data['column_name'].fillna(data['column_name'].mean(), inplace=True)
# Example: Fill missing categorical data with the mode
data['column_name'].fillna(data['column_name'].mode()[0], inplace=True)
# Step 2: Encoding Categorical Variables
# Identify categorical columns
categorical_cols = data.select_dtypes(include=['object']).columns
# Label encoding for categorical columns
label_encoder = LabelEncoder()
for col in categorical_cols:
data[col] = label_encoder.fit_transform(data[col])
# One-hot encoding (if needed)
# data = pd.get_dummies(data, columns=categorical_cols, drop_first=True)
# Step 3: Splitting the Dataset
X = data.drop('target_column', axis=1) # Features
y = data['target_column'] # Target variable
# Split the dataset into training and testing sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# Step 4: Feature Scaling (if needed)
scaler = StandardScaler()
X_train = scaler.fit_transform(X_train)
X_test = scaler.transform(X_test)
# Additional Data Preprocessing Steps (optional):
# - Feature engineering
# - Handling outliers
# - Removing duplicates
# - Handling imbalanced data
# - Text data preprocessing (e.g., tokenization, stemming, stopwords removal)
# Now, you have preprocessed data ready for analysis or machine learning tasks.
In this template:
You import the necessary libraries, including NumPy, Pandas, and scikit-learn.
You load your dataset using pd.read_csv() or the appropriate method for your data source.
You handle missing data by filling in missing values with appropriate strategies (mean, mode, etc.).
You encode categorical variables using label encoding or one-hot encoding.
You split your dataset into training and testing sets using train_test_split.
You perform feature scaling using standardization or other scaling methods, if necessary.
Additional preprocessing steps are included as comments and can be added based on your specific needs.
Remember to customize this template according to your specific dataset and preprocessing requirements. Data preprocessing may vary depending on the nature of your data and the machine learning or analysis task you're working on.