Evaluation of Deep Learning-based Road Segmentation Methods for Satellite Images
تفاصيل العمل
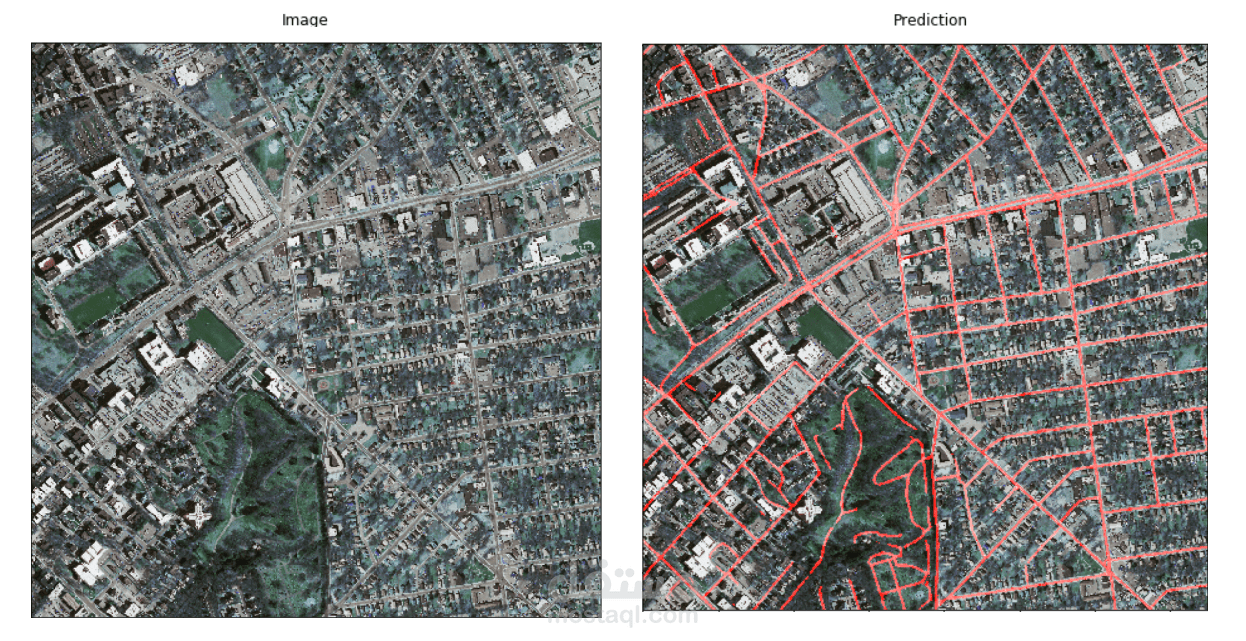
We provide a proof of concept that Encoder-Decoder models achieve great results on Road Segmentation and that is by applying 9 different architectures that depend on the Encoder-Decoder baseline. Encoder-Decoder segmentation techniques achieve robust performance in the two data sets we choose. The bullet points show the contributions of this thesis.
• First contribution, Encoder-Decoder Deep Convolutional Neural Networks have been proven to have great per- formance at many segmentation issues, which is why. Our contribution is to apply all current model archi- tectures that use the DCEP network as their primary base model to two open-source data sets from DeepG- lope and Massachusetts. We choose 9 different models Unet(34), FPN(24), PSPNet(67), Unet++(68), PAN(57), LinkNet(9), DeepLabv3(15), DeepLabv3+(5), and MA- Net(35).
• Second contribution, to ensure our approach is robust we use two different data sets DeepGlope and Massachusetts, and apply the same models to each one of them.
• Third contribution, we apply different data augmentation hyperparameters for angle rotation degrees we try [0:0], [-30:30], [-60,60], and [-90, 90], To make sure we pick up the most appropriate hyperparameters for all other models.
• Forth contribution, we evaluate all the models using Intersection Over Union (IOU) metric, and dice loss (DL) and give a brief comparison between each one of them and what is the most suitable model for each data set. After the experiments, we found that the 9 models obtain a great performance metric for the 2 data sets, but the result was so close to each other. The IOU (Intersection Over Union) was around 91% for the Massachusetts data set, and around 0.95% for the Deepglobe data set. The Encoder-Decoder network seems to be a great choice for these data sets