titanic machine learning
تفاصيل العمل
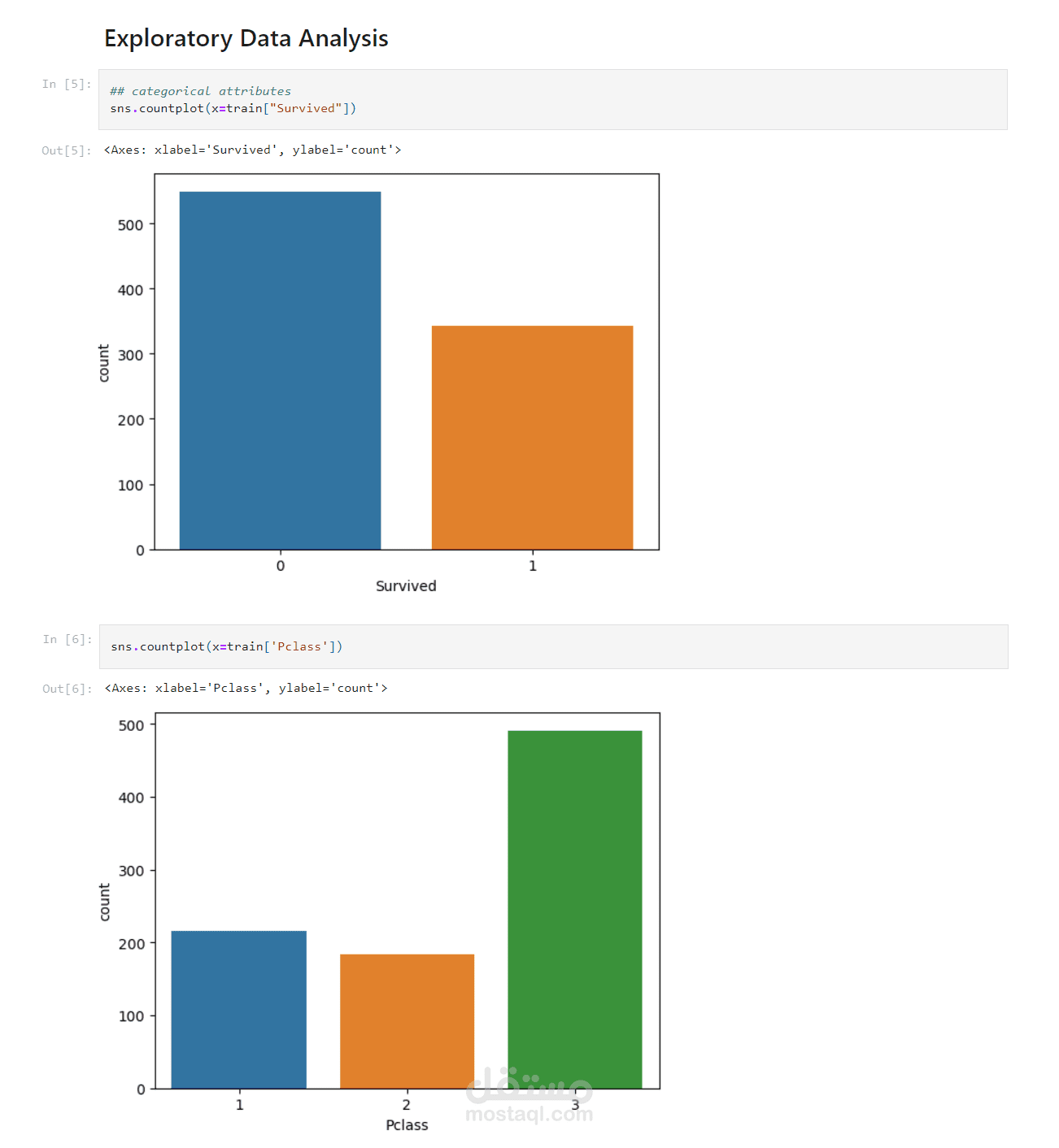
Titanic Survival Prediction Analysis - Classification
Dataset Information
The data has been split into two groups:
- training set (train.csv)
- test set (test.csv)
The training set should be used to build your machine learning models. For the training set, we provide the outcome (also known as the “ground truth”) for each passenger. Your model will be based on “features” like passengers’ gender and class. You can also use feature engineering to create new features.
The test set should be used to see how well your model performs on unseen data. For the test set, we do not provide the ground truth for each passenger. It is your job to predict these outcomes. For each passenger in the test set, use the model you trained to predict whether or not they survived the sinking of the Titanic.
We also include gender_submission.csv, a set of predictions that assume all and only female passengers survive, as an example of what a submission file should look like.
Download link for data : https://www.kaggle.com/c/...
# Libraries
- pandas
- matplotlib
- seaborn
- scikit-learn
# Algorithms
- Logistic Regression
- Decision Tree
- Random Forest
- Extra Tress
- XGBoost
- LightGBM
- CatBoost
The final code in Github : https://github.com/noured...