Loan Approval Prediction Model
تفاصيل العمل


This project predicts whether a loan application will be approved based on applicant details.
It applies Machine Learning models such as:
Logistic Regression (baseline)-
Logistic Regression + SMOTE (to balance data)-
Decision Tree Classifier (tuned hyperparameters)-
-----------------------------------------------
Project Workflow:
Data Exploration & Cleaning – inspected data types, missing values, and separated categorical & numerical features-
Feature Preparation – encoded variables like education & self_employed, and scaled numerical features-
Model Training – trained Logistic Regression, SMOTE-enhanced Logistic Regression, and Decision Tree-
Evaluation – compared models using Precision, Recall, F1-score, and Cross-validation with focus on business context-
(false positives are riskier).
-----------------------------------------------
Results:
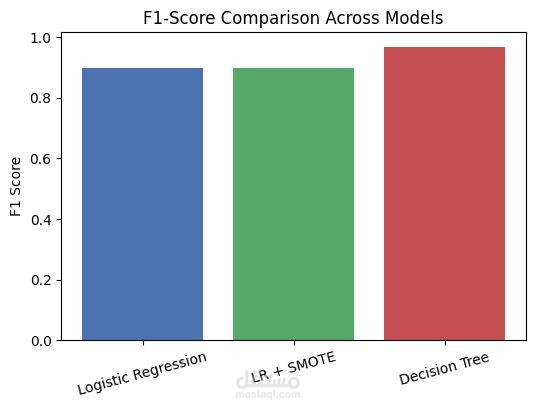
- Logistic Regression → Precision: ~0.88 | Recall: ~0.91 | F1: ~0.89 | CV: ~0.89
- Logistic Regression + SMOTE → Recall improved (~0.94) but added more false positives
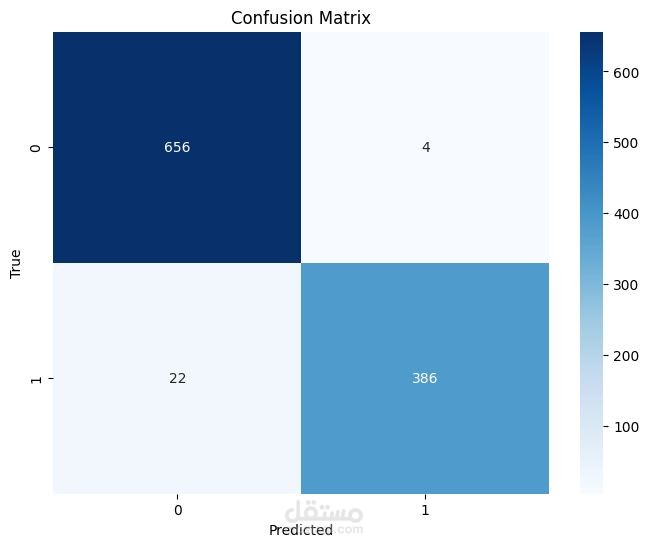
- Decision Tree Classifier → Precision: ~0.99 | Recall: ~0.94 | F1: ~0.97 | CV: ~0.97 ⭐
Final Choice: The Decision Tree achieved the best balance, with high precision and recall-
-----------------------------------------------
Business Impact:
The model helps banks minimize false approvals (reducing risk of defaults) while ensuring genuine applicants still receive loans.
-----------------------------------------------
Tech Stack:
Python | Pandas, NumPy | Matplotlib | scikit-learn, imbalanced-learn (SMOTE)